

von Brad Smith, Vice Chair & President bei Microsoft
Europa ist die Heimat von über 200 Sprachen und einem reichen kulturelles Erbe, das sich über Jahrtausende erstreckt. Millionen von Kulturgütern bewahren die Geschichten seiner Menschen. Doch diese Sprachen sind mehr als nur Erinnerungsträger – sie treiben Kultur und Wirtschaft an, weil sie Menschen verbinden, Kreativität fördern und Handel ermöglichen.
Mit der fortschreitenden Digitalisierung droht jedoch ein Verlust dieser sprachlichen und kulturellen Vielfalt. Der überwiegende Teil der Web‑Inhalte – Hauptquelle für das Training moderner Large Language Models (LLMs) – ist in Englisch und spiegelt häufig eine US‑amerikanische Perspektive wider. Die Europäische Kommission warnte kürzlich, dass Europas Vorhaben, sein gewaltiges kulturelles Erbe zu digitalisieren, noch „deutlich ausser Reichweite“ ist. Ohne rasches Gegensteuern bleibt dieses Ungleichgewicht nicht nur ein kulturelles, sondern auch ein wirtschaftliches Problem: Eine KI, die Europas Sprachen, Geschichte und Werte nicht versteht, kann Menschen, Unternehmen und Zukunft des Kontinents nicht gerecht werden.
Darum bekräftigen wir heute in Paris unser Engagement für Europas digitale Zukunft. Mit zwei neuen Initiativen wollen wir Europas kulturelle und sprachliche Vielfalt besser erschliessen und für alle zugänglich machen. Sie ergänzen unsere bestehenden Europäischen Digitalen Zusicherungen: Ausbau der KI‑ und Cloud‑Infrastruktur, stärkerer Datenschutz und digitale Resilienz, bessere Cybersicherheit sowie Unterstützung der digitalen Souveränität und Wirtschaft Europas.
Erstens: Zur Förderung mehrsprachiger KI-Modelle verlagern wir Mitarbeitende aus zwei Innovationszentren nach Strassburg – einem historischen Ankerplatz europäischer Kultur und Institutionen. Dort arbeiten sie am Ausbau mehrsprachiger Datensätze für die KI-Entwicklung, gestützt auf Microsoft Azure, Microsofts technologischer Expertise und starken Partnerschaften in Europa, um eine vielfältigere Sprachlandschaft bei KI-Modellen zu ermöglichen. Teil dieser Initiative ist auch ein Aufruf zur Erweiterung digitaler Inhalte in zehn europäischen Sprachen.
Zweitens: Damit Europas kultureller Reichtum auch digital erhalten und zugänglich bleibt, erweitern wir Microsofts „Culture AI“-Initiative. Sie dient dem Schutz von Sprachen, Bauwerken und Artefakten durch digitale Repliken und Datenpartnerschaften. Seit 2019 hat Microsoft unter anderem das antike Olympia in Griechenland, den Mont-Saint-Michel in Frankreich, den Petersdom in Rom sowie das Gedenken an die Landung der Alliierten in der Normandie digital dokumentiert. Heute geben wir bekannt, dass Microsoft ab Herbst gemeinsam mit dem französischen Kulturministerium und dem französischen Unternehmen Iconem eine digitale Nachbildung von Notre Dame erstellen wird – dem frisch restaurierten, 862 Jahre alten Meisterwerk der gotischen Architektur in Paris.
Diese Form der Unterstützung für Europas Vielfalt ist für Microsoft nicht neu. Unsere aktuellen Initiativen für Sprache und Kultur basieren auf über 40 Jahren Erfahrung in der Zusammenarbeit mit Ländern und Kulturen in Europa und weltweit. Uns ist bewusst: Um wirklich alle Menschen zu befähigen, müssen unsere Technologien in den Sprachen verfügbar sein, die sie sprechen. Deshalb unterstützt Windows heute mehr als 90 Sprachen – darunter sämtliche offiziellen Sprachen der Europäischen Union sowie Sprachen wie Baskisch, Katalanisch, Galicisch, Luxemburgisch, Valencianisch und viele weitere. Auch Microsoft 365 ist breit aufgestellt: Die Office-Anwendungen unterstützen mehr als 30 europäische Sprachen, einschliesslich aller Amtssprachen der Europäischen Union.
Warum wir die Sprachkluft dringend schliessen müssen
Die Europäische Union zählt 24 Amtssprachen – ergänzt durch zahlreiche weitere, die national oder regional anerkannt sind. Doch viele dieser Sprachen, selbst offizielle wie Dänisch, Finnisch, Schwedisch oder Griechisch, machen jeweils weniger als 0,6 % der weltweit verfügbaren Online-Inhalte aus. Andere wie Maltesisch, Irisch, Estnisch, Lettisch oder Slowenisch sind im Netz kaum vertreten. Gleichzeitig ist Englisch zwar nur für etwa 5 % der Weltbevölkerung die Muttersprache – dennoch entfallen rund 50 % der Web-Inhalte auf englische Texte. Damit prägen sie auch massgeblich die Daten, mit denen KI-Systeme trainiert werden.

Abbildung 1: CommonCrawl-Inhalt nach Sprache
Diese digitale Unterrepräsentation bleibt nicht folgenlos. Da LLMs stark auf Webinhalte als Trainingsbasis angewiesen sind, geraten Sprachen mit geringer Online-Präsenz schnell ins Hintertreffen – und damit auch in Gefahr, von künftigen KI-Diensten ausgeschlossen zu werden. Zwar sind grosse, universell einsetzbare Modelle in der Lage, mehrere Sprachen zu verarbeiten. Doch ihnen fehlt häufig das Gespür für sprachliche Feinheiten, kulturelle Kontexte und regionale Eigenheiten – alles entscheidend für inklusive, alltagsnahe Anwendungen. LLMs, die mit begrenztem Sprachmaterial trainiert wurden, sind oft weniger präzise, neigen stärker zu Halluzinationen und Fehlern, tun sich schwer mit dem Wortschatz und zeigen deutlichere Verzerrungen(1).
Ein Beispiel: Llama 3.1, ein beliebtes Open-Source-Modell, zeigt in Tests einen Leistungsabfall von über 15 Prozentpunkten zwischen Antworten auf Englisch und Griechisch – und sogar über 25 Punkten im Vergleich zwischen Englisch und Lettisch. Wäre dieses Modell eine Schülerin, wäre sie im Fach Englisch Klassenbeste, in Griechisch mittelmässig und in Lettisch am unteren Ende der Leistungsskala. Solche Unterschiede zwischen den Sprachen zeigen sich quer durch alle gängigen LLM-Benchmark-Tests (2).
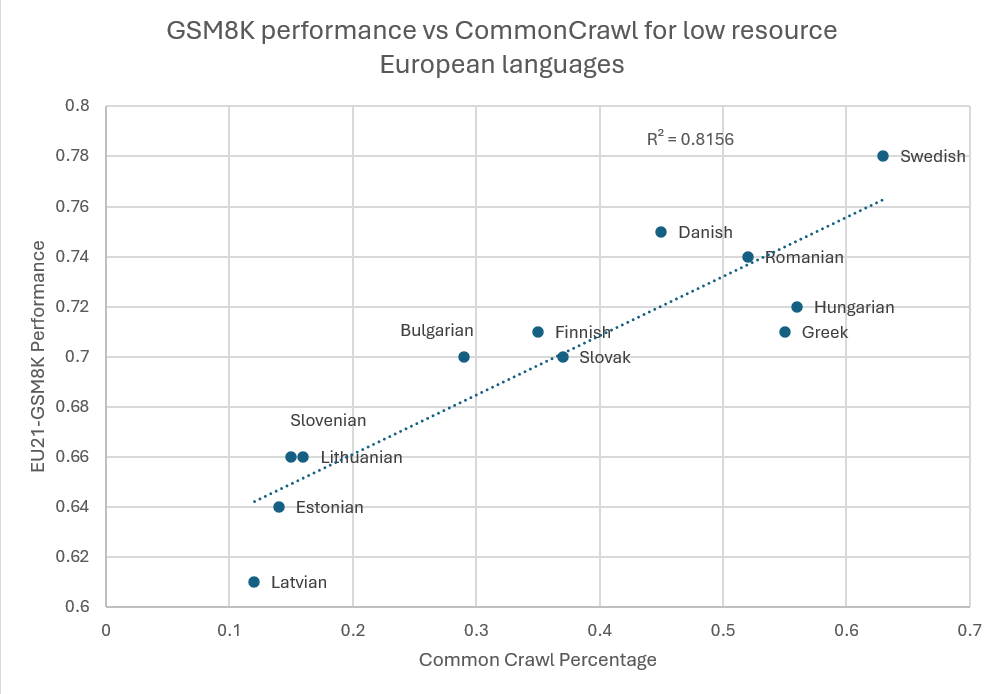 Abbildung 2: GSM8K-Leistung im Vergleich zu CommonCrawl für europäische Sprachen mit geringen Ressourcen
Abbildung 2: GSM8K-Leistung im Vergleich zu CommonCrawl für europäische Sprachen mit geringen Ressourcen
Viele Sprachen mit tief verwurzeltem kulturellem Erbe, etwa Bretonisch, Okzitanisch oder Rätoromanisch, werden von heutigen gängigen KI-Systemen kaum berücksichtigt. Dabei stuft die UNESCO sie als gefährdet ein.
Sprache ist Wirtschaftsfaktor
Diese ungleiche Entwicklung von Sprachmodellen hat direkte wirtschaftliche Folgen. Wenn KI-Systeme eine Regionalsprache nicht verstehen oder nicht in ihr antworten können, schränkt das den Zugang zu Diensten und Chancen ein und bremst sowohl lokale Unternehmen als auch das gesamtwirtschaftliche Wachstum.
In den kommenden zehn Jahren wird die breite Anwendung von KI über alle Branchen hinweg zu einem zentralen Motor für Innovation und Produktivität. So wie einst Elektrizität oder andere Schlüsseltechnologien, markiert KI den nächsten Schritt der Industrialisierung.
Doch für Gemeinschaften, deren Sprache online kaum vertreten ist, bleiben die Vorteile oft unerreichbar. Man denke etwa an eine Unternehmerin auf Malta, die ausschliesslich Maltesisch spricht: Für Aufgaben wie Marktanalysen oder Content-Erstellung gibt es bislang kaum leistungsfähige KI-Tools in dieser Sprache, was ihren Zugang erheblich einschränkt. Oder denken wir an einen polnischsprachigen Schüler in einer Kleinstadt ausserhalb Warschaus, der keine KI-gestützten Lernangebote in seiner Sprache findet. Das beeinträchtigt seine Bildungschancen. Selbst wenn eine KI-Plattform eine Sprache grundsätzlich unterstützt, kann die Nutzererfahrung oft deutlich hinter den Erwartungen zurückbleiben.
Europäische Regierungen und Institutionen haben erkannt, wie entscheidend es ist, dieser Herausforderung aktiv zu begegnen. Um im KI-Zeitalter wirtschaftlich wettbewerbsfähig zu bleiben, muss Europa Sprachbarrieren abbauen und die Verbreitung von KI über den gesamten Kontinent hinweg fördern. Laut Europäischer Kommission nutzen aktuell nur 13,5 % der Unternehmen in der EU Künstliche Intelligenz. Der EU-Aktionsplan „AI Continent“ betont: Würden Sprachbarrieren im Binnenmarkt überwunden, könnte der innergemeinschaftliche Handel um bis zu 360 Milliarden Euro wachsen.
Neue Massnahmen gegen die Sprachlücke
Um diese Lücke zu schliessen, arbeitet Microsoft mit europäischen Partnern daran, mehrsprachige Daten besser verfügbar zu machen. Gemeinsam mit dem ICube Laboratory an der Universität Strassburg, einer Forschungseinrichtung mit Fokus auf Ingenieurwissenschaften, Informatik und Bildverarbeitung, unterstützen wir die Entwicklung und das Training von KI-Systemen. Dafür entsenden wir Mitarbeitende aus unserem Microsoft Open Innovation Center (MOIC) sowie dem AI for Good Lab nach Strassburg.
Unterstützt wird das Team von einem globalen internen Netzwerk aus über 70 Microsoft-Ingenieur*innen, Datenwissenschaftler*innen und Politikexpert*innen. Im Rahmen dieser Kooperation zwischen MOIC, dem AI for Good Lab und der Universität Strassburg finanzieren wir ausserdem zwei Postdoc-Stellen und stellen bis zu 1 Million US-Dollar in Azure-Credits zur Verfügung.
Zum Start wird das Team auf den eigenen Bestand an mehrsprachigen Daten von Microsoft zurückgreifen und diesen für die europäische Öffentlichkeit, einschliesslich Open-Source-Entwickler*innen, transparent und zugänglich machen. Dazu zählen beispielsweise mehrsprachige Textdaten von GitHub und Sprachdatensätze. MOIC und GitHub kooperieren dabei mit Hugging Face –-einer führenden Plattform für kollaborative KI-Entwicklung – um diese Daten bereitzustellen und breit verfügbar zu machen. Diese Initiative baut auf unserer bestehenden Zusammenarbeit mit Hugging Face auf, über die wir bereits zahlreiche Open-Source-Modelle aus der Hugging-Face-Bibliothek für die direkte Bereitstellung im Azure Model Catalogue integriert haben. Ein aktuelles Beispiel: Vergangene Woche wurde das neueste Modell für mehrsprachige KI veröffentlicht – SmoILM3, ein hochperformantes Modell mit 3 Milliarden Parametern, das sechs Sprachen unterstützt: Englisch, Französisch, Spanisch, Deutsch, Italienisch und Portugiesisch.
Darüber hinaus wird MOIC mit Common Crawl zusammenarbeiten – einem der grössten frei zugänglichen Repositorien für automatisiert gesammelte Webdaten. MOIC wird die Arbeit dort finanziell unterstützen und den Einsatz von Muttersprachler*innen fördern, um europäische Sprachdaten im öffentlich zugänglichen Common Crawl-Datensatz zu kennzeichnen und gezielt zu ergänzen.
Ausserdem veröffentlichen das MOIC und das AI for Good Lab einen Förderaufruf, um das Angebot an digitalen Inhalten für zehn europäische Sprachen gezielt auszubauen. Ziel ist es, Textsammlungen auf verantwortungsvolle und ethisch vertretbare Weise zu Bedingungen der jeweiligen Rechteinhaber für die Entwicklung und Nutzung mehrsprachiger KI-Anwendungen zugänglich zu machen. Förderanträge können ab dem 1. September 2025 über die Website des AI for Good Lab eingereicht werden. Bei der Auswahl der geförderten Projekte liegt der Fokus auf Sprachen, die im digitalen Raum bislang nur schwach vertreten sind, etwa Estnisch, Elsässisch, Slowakisch, Griechisch oder Maltesisch. Die geförderten Organisationen erhalten Azure-Guthaben sowie technische und ingenieurtechnische Unterstützung, um die Digitalisierung und Bereitstellung ihrer Inhalte zu realisieren.
Der Zuwachs an mehrsprachigen Daten ist entscheidend. Doch auch bessere Technologien und das richtige Know-how spielen eine zentrale Rolle. Viele Sprachen nutzen Schriftsysteme, die für KI-Modelle, die ursprünglich auf das lateinische Alphabet ausgelegt sind, besondere Herausforderungen darstellen. So haben etwa kyrillische Buchstaben, das griechische Alphabet oder die verbundene Schrift des Arabischen jeweils eigene Eigenschaften. Standard-„Tokenizer“ zerlegen diese Schriften oft auf wenig geeignete Weise, was die Lernfähigkeit der Modelle einschränkt – insbesondere beim Verständnis von Kontext oder der korrekten Schreibung. Neue technische Ansätze, die Modelle befähigen, mit verschiedenen Schriften einheitlich umzugehen, bieten hier viel Potenzial. Ebenso wichtig sind verbesserte Verfahren zur Erstellung synthetischer Daten und deren sorgfältige Verarbeitung und Kuratierung, vor allem dann, wenn hiermit auch Datenschutz und sensible Inhalte zuverlässig geschützt und bewahrt werden können.
Das MOIC und das AI for Good Lab werden daran arbeiten, Wissen, Tools und Fähigkeiten zu entwickeln und zugänglich zu machen, um bestehende Herausforderungen gezielt zu adressieren und europäische Entwickler*innen zu stärken. Das AI for Good Lab wird zudem einen Leitfaden veröffentlichen, der aufzeigt, wie hochwertige Sprachdatensätze erstellt und lokale LLMs effizient trainiert werden können, um das volle Potenzial vorhandener Daten auszuschöpfen.
Beide Teams unterstützen relevante Forschungsprojekte, organisieren Fachveranstaltungen, investieren gemeinsam in Data-Commons-Initiativen und sorgen dafür, dass Know-how und Technologien dort ankommen, wo sie am dringendsten benötigt werden. Sie begleiten ausserdem weiterhin Projekte wie jene des Barcelona Supercomputing Center, des Basque Center for Language Technology und der Universität Santiago de Compostela. Ziel ist es, KI-Modelle in Spanisch, Katalanisch, Baskisch und Galicisch über die Azure AI Foundry bereitzustellen.
Diese Initiative gibt Entwickler*innen die Möglichkeit, KI-Anwendungen in den offiziellen Landessprachen Spaniens zu bauen und trägt damit gezielt zu mehr Innovation und Inklusion bei.
Um verantwortungsvolle KI-Forschung voranzutreiben und die Sprachlücke weiter zu schliessen, startet Microsoft zwei neue akademische Kooperationen in Europa: mit der Universität Strassburg sowie der IE University School of Science & Technology in Spanien. Gemeinsam mit der Universität Strassburg stellen das AI for Good Lab und das MOIC Azure-Stipendien zur Verfügung, um gemeinsame Forschungsprojekte im Bereich Künstliche Intelligenz zu fördern. An der IE University of Science & Technology wird das AI for Good Lab Forschungsprojekte zu wenig vertretenen Sprachen unterstützen – inklusive Förderungen für praxisnahe Abschlussprojekte, die neue KI-Lösungen rund um Sprache und Inklusion vorantreiben sollen.
Neue Impulse für den digitalen Schutz des kulturellen Erbes Europas
Seit 2019 verfolgt Microsofts „Culture AI“-Initiative das Ziel, weltweit Sprachen, Orte, Geschichten und Artefakte mithilfe künstlicher Intelligenz zu bewahren. Getragen vom AI for Good Lab und unterstützt durch Partnerschaften mit NGOs, Universitäten, Regierungen und Kultureinrichtungen, unterstützt die Initiative Projekte zur Digitalisierung und Sicherung kulturellen Erbes – von bedrohten Sprachen bis hin zu ikonischen Wahrzeichen, etwa in Frankreich, Rom oder Griechenland.
Ob durch digitale Repliken historischer Stätten oder durch die bessere Zugänglichkeit von Museumssammlungen, das übergeordnete Ziel ist klar: kulturelle Identität und Vielfalt sollen nicht nur bewahrt, sondern im digitalen Zeitalter breiter zugänglich, sichtbarer und inklusiver gemacht werden.Heute kündigen wir unser nächstes Projekt an: Gemeinsam mit dem französischen Kulturministerium und dem französischen Unternehmen Iconem schaffen wir eine digitale Nachbildung von Notre Dame in Paris – einem Bau- und Kulturdenkmal, das über Jahrhunderte hinweg Geschichte geschrieben hat. Der Bau begann im Jahr 1163 und dauerte fast zwei Jahrhunderte. Das Ergebnis: ein 128 Meter langes Meisterwerk der Gotik mit zwei Türmen, die 69 Meter hoch über der Seine thronen. Nach dem verheerenden Brand im Jahr 2019 wurde die Kathedrale Ende 2024 wieder für die Öffentlichkeit geöffnet. Für dieses Projekt greifen wir auf Technologien und Verfahren zurück, die wir bereits 2023 mit Iconem und dem Vatikan beim digitalen Zwilling des Petersdoms eingesetzt haben – basierend auf über 400.000 Fotos und hochentwickelten KI-Algorithmen.
Wie bei der detailgetreuen digitalen Erfassung des Petersdoms wird auch der digitale Zwilling von Notre Dame jedes architektonische Detail dauerhaft digital sichern. Ziel ist es, die Struktur, Geschichte und Symbolkraft dieses einzigartigen Bauwerks für kommende Generationen zu bewahren und zugänglich zu machen. Mithilfe fortschrittlicher Bildgebung und Künstlicher Intelligenz entsteht ein digitales Abbild, das wir dem französischen Staat übergeben – für den Einsatz durch Denkmalschützer*innen und zur Ausstellung im künftigen Musée Notre Dame de Paris.
Neben dem Projekt rund um Notre Dame kündigen wir heute auch eine neue Partnerschaft mit der Bibliothèque nationale de France an – in Zusammenarbeit mit Iconem. Ziel ist die Digitalisierung von fast 1.500 Bühnenmodellen aus Inszenierungen der Opéra National de Paris, die zwischen 1800 und 1914 entstanden sind. Die digitalisierten Modelle werden im Rahmen interaktiver, edukativer Formate und Ausstellungen erlebbar gemacht und zugleich als Datensatz auf der Plattform Gallica der Bibliothèque nationale de France für KI-gestützte Kultur- und Forschungsprojekte bereitgestellt.
Darüber hinaus starten wir eine weitere Zusammenarbeit mit dem Musée des Arts Décoratifs, um die detaillierten digitalen Beschreibungen von rund 1,5 Millionen Objekten vom Mittelalter bis zur Gegenwart öffentlich zugänglich zu machen. Damit erhalten Forschende aus den Bereichen Geschichte, Kunstgeschichte und Denkmalpflege direkten Zugriff auf neue Informationsquellen als Grundlage für eigene KI-gestützte Analysen, Studien und Anwendungen.
Ausblick: Ein Ansatz mit Haltung
Wir gehen diese neuen Schritte mit Demut und Respekt – im Bewusstsein, dass die Bewahrung Europas sprachlicher und kultureller Vielfalt eine Aufgabe ist, die von Europäer*innen geführt und getragen werden muss. Die Europäische Union hat bereits eine länderübergreifende Initiative gestartet, um Sprachdaten zu bündeln und das kulturelle Erbe in all seinen Formen zu digitalisieren. Unsere Rolle besteht darin, diese und ähnliche Anstrengungen zu unterstützen und sinnvoll zu ergänzen. Keines der heute vorgestellten Projekte schafft proprietäre Daten oder Technologien für Microsoft.
Langfristig lässt sich der Bedarf am besten decken, indem wir mehr Menschen in Europa mit den KI-Kenntnissen ausstatten, die sie für diese Aufgabe befähigen. Die Europäische Kommission hat kürzlich festgestellt, dass ein Mangel an digitalen Kompetenzen im Kultursektor die Digitalisierung des europäischen Kulturerbes ausbremst. Um diese Lücke zu schließen, werden das MOIC und das AI for Good Lab ihre Erkenntnisse und Erfahrungen weitergeben – praxisnah und zugänglich.
Technologie sollte die Vielfalt der Menschheit widerspiegeln, nicht vereinfachen oder verdrängen. Wenn wir jetzt bewusst handeln, können wir sicherstellen, dass KI nicht zur Gefahr für sprachliche und kulturelle Identität wird, sondern ihr stärkster Verbündeter.
Das ist eine der zentralen Gerechtigkeitsfragen unserer Zeit. Und wenn wir gemeinsam handeln – mit Klarheit, Engagement und Tempo – können wir die digitale Zukunft Europas so gestalten, dass sie jede Sprache, jede Kultur und jede Gemeinschaft würdigt.
(1) P. Rohera, C. Ginimav, G. Sawant, and R. Joshi, “Better To Ask in English? Evaluating Factual Accuracy of Multilingual LLMs in English and Low-Resource Languages,” Apr. 28, 2025, arXiv: arXiv:2504.20022. doi: 10.48550/arXiv.2504.20022.
(2) K. Thellmann et al., “Towards Multilingual LLM Evaluation for European Languages,” Oct. 17, 2024, arXiv: arXiv:2410.08928. doi: 10.48550/arXiv.2410.08928.




