Apuntar los avances en IA hacia la búsqueda biomédica
El 11 de marzo se cumplió un año desde que COVID-19 fue declarado pandemia por la Organización Mundial de la Salud. En ese momento, el virus ya se había extendido a 114 países y había matado a más de 4 mil personas en todo el mundo. Washington fue el primer estado de los Estados Unidos que se enfrentó a un brote, que se extendió a un par de millas de mi casa en Kirkland. El mundo estaba envuelto en miedo.
Al enfrentar la pandemia, los investigadores en biología, medicina y epidemiología se apresuraron a comprender mejor el Sars-CoV2 y desarrollar enfoques para tratar el COVID-19. Sus conocimientos y hallazgos generaron una explosión de información: se publicaron decenas de miles de artículos de investigación en los primeros meses. Hasta la fecha, se han publicado casi medio millón de artículos. Y este trabajo reciente se basa en una base masiva de cientos de miles de publicaciones relevantes que se remontan a décadas, incluidos los hallazgos sobre otros virus de la familia de los coronavirus, la investigación de las respuestas inmunitarias a las infecciones respiratorias y los avances con las vacunas basadas en ARN.
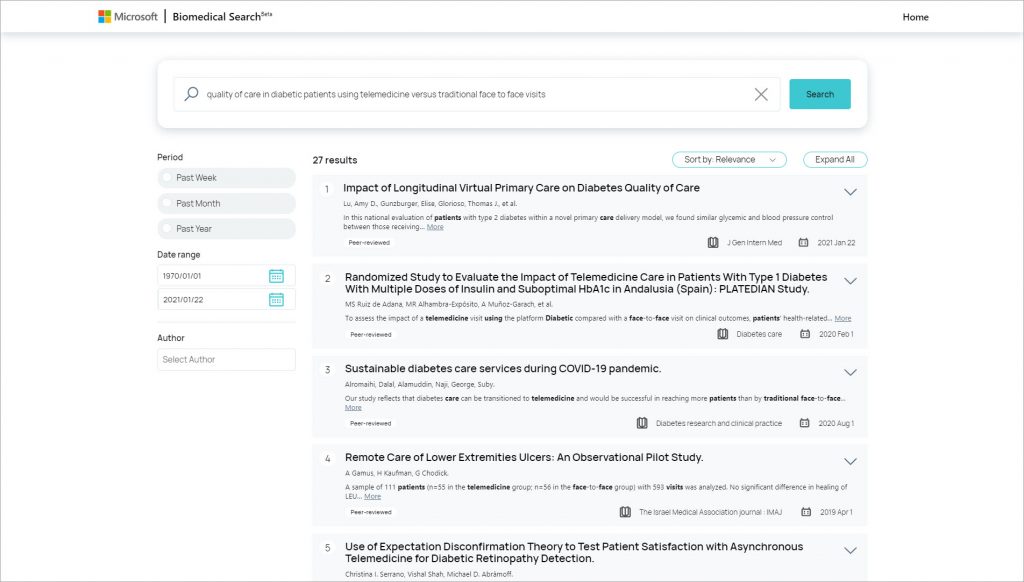
Al reconocer que las herramientas para navegar por la información jugarían un papel fundamental en la lucha contra el virus, los equipos de Microsoft se inspiraron para pensar de manera más profunda en la búsqueda y recuperación de información biomédica, lo que impulsó nuevos proyectos. Por esta razón, anunciamos la disponibilidad de Microsoft Biomedical Search, un prototipo de investigación que permite a los buscadores consultar literatura biomédica con consultas en lenguaje natural en lugar de palabras clave.
Microsoft Biomedical Search se basa en varios hilos de trabajo. Al comienzo de la pandemia, colaboramos con colegas de la Biblioteca Nacional de Medicina (NLM, por sus siglas en inglés), el Instituto Allen de IA, la Oficina de Ciencia y Tecnología de la Casa Blanca (OSTP, por sus siglas en inglés) y otras organizaciones para construir el conjunto de datos de investigación abierta COVID-19 (CORD -19). Este recurso, disponible de manera gratuita, de contenido legible por máquina sobre el grupo de virus coronavirus, ha estimulado numerosos proyectos de investigación en todo el mundo sobre búsqueda biomédica y visualización científica.
En otro esfuerzo, buscamos una mejor comprensión de las preguntas emergentes y las necesidades de información al acercarnos a científicos y médicos en la primera línea de la pandemia. Como parte de este trabajo, nos relacionamos con colegas de la Clínica Cleveland sobre los desafíos relacionados con la búsqueda de información. El equipo de la Clínica Cleveland reunió a un grupo diverso de biólogos y médicos para crear una lista de preguntas que fueran representativas de sus crecientes necesidades de información, para su búsqueda de investigación científica en las fronteras de la comprensión y para ayudar con la atención de los pacientes con COVID-19.
Con Microsoft Biomedical Search, hemos reunido grandes conjuntos de datos de literatura biomédica, cargas de trabajo de consultas representativas y avances en modelos de lenguaje neuronal a gran escala para mejorar la búsqueda biomédica. En particular, hemos buscado capacidades que permitan a los buscadores especificar mejor lo que quieren decir con la precisión del lenguaje natural.
Microsoft Biomedical Search muestra los resultados más relevantes de más de 20 millones de documentos de CORD-19, Microsoft Academic, PubMed y PubMed Central y se basa en tres esfuerzos de IA interrelacionados: modelos PubMedBERT, MetaAdaptRank y SaliencyMeasure.
PubMedBERT es un modelo de lenguaje a gran escala que se entrenó de manera previa en texto biomédico en lugar de en una combinación de lenguaje de dominio general y lenguaje de dominio específico. El modelo fue entrenado con anterioridad desde cero con 3 mil millones de palabras específicas para biomedicina. Hemos descubierto que el modelo supera a todos los modelos de lenguaje anteriores en aplicaciones de procesamiento biomédico del lenguaje natural.
MetaAdaptRank ayuda a determinar con precisión la relevancia al aliviar los problemas comunes asociados con la clasificación de los resultados de búsqueda de la investigación. Los sistemas de recuperación de información a menudo no identifican toda la información relevante porque las consultas y los documentos utilizan términos diferentes para describir el mismo concepto. Por ejemplo, esta discrepancia puede ocurrir cuando un buscador no está familiarizado con la nueva terminología. MetaAdaptRank puede aprender la semántica de dominios especializados para clasificar los resultados con mayor precisión incluso para temas o palabras clave para los que la información es escasa.
SaliencyMeasure utiliza el aprendizaje por refuerzo para predecir la posible importancia futura de un artículo científico, lo que ayuda a equilibrar la clasificación de publicaciones o autores más antiguos y recientes en lugar de depender únicamente de las citas.
Nos complace poner Microsoft Biomedical Search en manos de científicos, médicos, epidemiólogos y expertos en salud pública en investigación biomédica. Es cierto que hay mucho más por hacer y más por aprender para ayudar a los científicos a navegar la explosión de información en biomedicina. Agradecemos los comentarios de la comunidad biomédica para ayudarnos a seguir avanzando.
Conozcan más: