
Por Jennifer Langston
Atualmente, as pessoas que desejam reservar férias online provavelmente têm preferências muito diferentes daquelas que tinham antes da pandemia de COVID-19.
Em vez de voar para uma praia exótica, elas podem se sentir mais confortáveis fazendo viagens de carro. Com opções limitadas para jantar fora, ter uma cozinha completa pode ser essencial. Quartos ou cabines de hotéis podem ser mais atraentes do que hotéis com saguões compartilhados.
Inúmeras empresas usam mecanismos de recomendação online para mostrar aos clientes produtos e experiências que correspondem aos seus interesses. Ainda assim, os modelos tradicionais de aprendizado de máquina que preveem o que as pessoas podem preferir geralmente se baseiam em dados de experiências anteriores. Isso significa que eles não são necessariamente capazes de perceber mudanças rápidas nas preferências do consumidor, a menos que sejam treinados novamente com novos dados.
O Personalizador, que faz parte do Azure Cognitive Services e da plataforma IA do Azure, usa uma abordagem mais avançada para aprendizado de máquina chamada aprendizado por reforço, em que os agentes de IA podem interagir e aprender com seu ambiente em tempo real.
A técnica costumava ser usada principalmente em laboratórios de pesquisa. Mas agora, está abrindo caminho para mais produtos e serviços da Microsoft – dos Serviços Cognitivos do Azure que os desenvolvedores podem conectar em aplicativos e sites a sistemas autônomos que os engenheiros podem usar para refinar os processos de fabricação. O Azure Machine Learning também está visualizando ofertas de aprendizado de reforço baseado em nuvem para cientistas de dados e profissionais de aprendizado de máquina.

“Percorremos um longo caminho nos últimos dois anos, quando tínhamos muitos projetos de prova de conceito dentro da Microsoft e implantações com alguns clientes”, disse Rafah Hosn, diretor sênior do laboratório de Pesquisa da Microsoft em Nova York. “Agora estamos realmente progredindo muito bem em coisas que podem ser embaladas em plástico e direcionadas para um determinado conjunto de problemas”.
Z-Tech, o centro de tecnologia da Anheuser-Busch InBev, está usando o Personalizador para fornecer recomendações customizadas em um mercado online para melhor atender pequenas mercearias em todo o México. Outros clientes e parceiros da Microsoft estão empregando o aprendizado de reforço para detectar anomalias de produção e desenvolver robôs que podem se ajustar a condições imprevisíveis do mundo real – com modelos que podem aprender com dicas ambientais, comentários de especialistas ou comportamento do cliente em tempo real.
Depois que a Microsoft começou a usar o Personalizador em sua página inicial para personalizar os produtos exibidos para cada visitante, a empresa teve um aumento de 19 vezes no envolvimento com os produtos escolhidos pelo Personalizador. A empresa também usou o Personalizador internamente para selecionar as ofertas, produtos e conteúdo certos no Windows, Edge e Xbox. Esses cenários estão proporcionando um aumento de até 60% no engajamento em bilhões de personalizações a cada mês.
O Teams também usou o aprendizado de reforço para encontrar o buffer de jitter ideal para uma videoconferência, que compensa atrasos de informações em escala de milissegundos para fornecer melhor continuidade de conexão, enquanto o Azure está explorando a otimização baseada no aprendizado de reforço para ajudar a determinar quando reinicializar ou corrigir as máquinas virtuais.
Como os modelos de aprendizagem por reforço aprendem com feedback instantâneo, eles podem se adaptar rapidamente a circunstâncias variáveis ou imprevisíveis. Assim que a pandemia da COVID-19 chegou, algumas empresas não tinham ideia do que esperar, já que os comportamentos de compra e viagens das pessoas mudaram da noite para o dia, disse Jeff Mendenhall, gerente de programa principal da Microsoft para o Personalizador.
“Todo o seu histórico de modelagem e conhecimento especializado foram jogados pela janela”, disse Mendenhall. “Mas com o aprendizado por reforço, o Personalizador pode atualizar o modelo a cada minuto, se necessário, para aprender e responder aos comportamentos reais e atuais do usuário.”
No aprendizado por reforço, um agente de IA aprende em grande parte por tentativa e erro. Ele testa diferentes ações em um mundo real ou simulado e recebe uma recompensa quando as ações alcançam o resultado desejado – seja um cliente apertando o botão para confirmar uma reserva de férias ou um robô descarregando com sucesso um saco de moedas pesado.
Treinar um agente de IA por meio do aprendizado por reforço é semelhante a ensinar um cachorro a fazer um truque, disse Hosn. Ele recebe uma recompensa quando toma decisões que geram o resultado desejado e aprende a repetir as ações que obtêm mais recompensas. Mas em cenários complicados do mundo real, explorar o vasto universo de ações potenciais e encontrar uma sequência ideal de decisões pode ser muito mais complicado.
Na 34ª Conferência sobre Sistemas de Processamento de Informação Neural (NeurIPS 2020) que aconteceu esta semana, os pesquisadores da Microsoft apresentaram 17 trabalhos de pesquisa que marcam um progresso significativo na abordagem de alguns dos maiores desafios do campo. Ao investir em equipes de aprendizado de reforço em sua rede de laboratórios de pesquisa da Microsoft, a empresa diz que está desenvolvendo um portfólio de abordagens para resolver diferentes problemas e explorar vários caminhos para descobertas em potencial.

Essas equipes têm se concentrado no desenvolvimento de uma compreensão robusta dos elementos fundamentais do aprendizado por reforço e na criação de soluções práticas para os clientes – não apenas demonstrações de novidades, dizem os pesquisadores.
Eles passaram muito tempo descobrindo em quais cenários o aprendizado por reforço é adequado para resolver, bem como investigando os fundamentos técnicos para entender por que algo funciona e como repeti-lo, disse John Langford, gerente de pesquisa parceiro da Microsoft Research Lab – Nova York.
“No momento, há uma grande lacuna entre as aplicações únicas em que você pode fazer os PhDs trabalharem muito e descobrir uma maneira de fazer isso funcionar, em vez de desenvolver um sistema rotineiramente útil que pode ser usado continuamente”, disse Langford.
“Todas as nossas pesquisas de aprendizagem por reforço na Microsoft realmente se enquadram em duas grandes frentes – como podemos resolver os desafios que os clientes estão trazendo para nós e quais são as bases que podemos usar para construir soluções replicáveis e confiáveis?” ele disse.
Uma abordagem diferente para aprendizado de máquina
O aprendizado por reforço usa uma abordagem fundamentalmente diferente do aprendizado supervisionado, uma técnica de aprendizado de máquina mais comum em que os modelos aprendem a fazer previsões a partir de exemplos de treinamento que receberam.
Se uma pessoa está tentando aprender francês, expor-se ao texto francês, regras gramaticais e vocabulário está mais perto de uma abordagem de aprendizagem supervisionada, disse Raluca Georgescu, um engenheiro de software de pesquisa que trabalha no Projeto Paidia no laboratório Microsoft Research Cambridge UK.
Com uma abordagem de aprendizagem por reforço, eles iriam para a França e aprenderiam falando com as pessoas. Eles seriam penalizados com olhares perplexos se dissessem a coisa errada e seriam recompensados com um croissant se pedissem corretamente, disse ela.
Um agente de aprendizagem por reforço aprende interagindo com seu ambiente, seja no mundo real ou em um ambiente simulado que lhe permite explorar diferentes opções com segurança. Ele executa uma ação e espera para ver se resulta em um resultado positivo ou negativo, com base em um sistema de recompensa que foi estabelecido. Depois que o feedback é recebido, o modelo descobre se a decisão foi boa ou ruim e se atualiza de acordo.
É uma forma realmente simples de aprendizagem que é endêmica no mundo natural, disse Langford.
“Mesmo os vermes podem fazer o aprendizado por reforço – eles podem aprender a ir em direção às coisas e evitá-las com base em algum feedback”, disse Langford. “Essa capacidade de aprender em um nível muito básico com seu ambiente é algo super natural para nós, mas no aprendizado de máquina é um pouco mais complicado e delicado e requer mais reflexão do que aprendizado supervisionado.”
Os novos artigos apresentados no NeurIPS esta semana oferecem contribuições significativas em três áreas-chave de pesquisa: aprendizagem por reforço em lote, exploração estratégica com observações ricas e aprendizagem de representação. Juntos, dizem os pesquisadores, esses avanços visam aumentar a eficiência dos modelos e expandir o escopo dos problemas que o aprendizado por reforço pode resolver.
De laboratórios de pesquisa a produtos do mundo real
O Personalizador, o primeiro Serviço Cognitivo do Azure a ser desenvolvido com base no aprendizado por reforço, surgiu de uma estreita colaboração entre pesquisadores da Microsoft e especialistas em produtos do Azure. Eles queriam ajudar os desenvolvedores a fornecer o conteúdo certo facilmente para os usuários certos no momento certo, sem exigir um conhecimento profundo de aprendizado de máquina.
O Consultor de Métricas, um novo Serviço Cognitivo do Azure agora disponível em visualização pública, também usa aprendizado de reforço para incorporar feedback e tornar os modelos mais adaptáveis ao conjunto de dados de um cliente, o que ajuda a detectar anomalias mais sutis em sensores, processos de produção ou métricas de negócios.
O Personalizador seleciona automaticamente o que mostrar a alguém que está visitando um site ou qual pergunta um chatbot deve fazer a seguir para impulsionar um negócio ou resultado de experiência desejado. Isso pode significar fazer uma pessoa se comprometer com hábitos alimentares mais saudáveis ou experimentar uma nova experiência de jogo. O agente aprende por tentativa e erro qual conteúdo é mais útil ou persuasivo para diferentes tipos de usuários.

Ao tentar fazer uma recomendação de vídeo, por exemplo, o que alguém prefere assistir pode ser determinado pela hora do dia, se eles estão sentados em casa ou se movimentando, ou quanta bateria seu dispositivo ainda tem. O Personalizador aprende com as escolhas ou ações feitas por clientes com características semelhantes.
Z-Tech, o centro de tecnologia da empresa multinacional de bebidas e cervejarias AB InBev, começou a usar o Personalizador neste outono para fornecer recomendações customizadas para pequenas lojas no México que fazem pedidos por meio do mercado online MiMercado. Notou-se um aumento de quase 100% nas taxas de cliques para produtos personalizados e um aumento de 67% na conversão de interesse do cliente em pedidos.
“À medida que estávamos aprendendo sobre os recursos da plataforma Azure, o Personalizador surgiu como algo de vanguarda e muito inovador e resolveu uma necessidade para nós”, disse Luiz Gondim, diretor de tecnologia global da Z-Tech, que pretende trazer soluções baseadas em dados para pequenas e médias empresas.
No passado, os produtos apresentados no MiMercado eram os mesmos para todos os clientes. A Z-Tech estava interessada em usar IA para fazer recomendações personalizadas e mais úteis para uma loja de esquina individual que vende de tudo, desde cerveja e suprimentos de panificação até batatas fritas e ração para animais de estimação.
O Personalizador teve dois benefícios diferenciadores, disse Richard Sheng, diretor global de ciência de dados e análise da Z-Tech.
“Os modelos de aprendizagem por reforço, por sua própria natureza, geralmente requerem menos dados porque usam o contexto atual para gerar recomendações e aprender por meio do feedback do usuário”, disse ele. “E ter os modelos já desenvolvidos e incluídos em uma API que podemos usar dessa forma plug-and-play foi muito útil.”
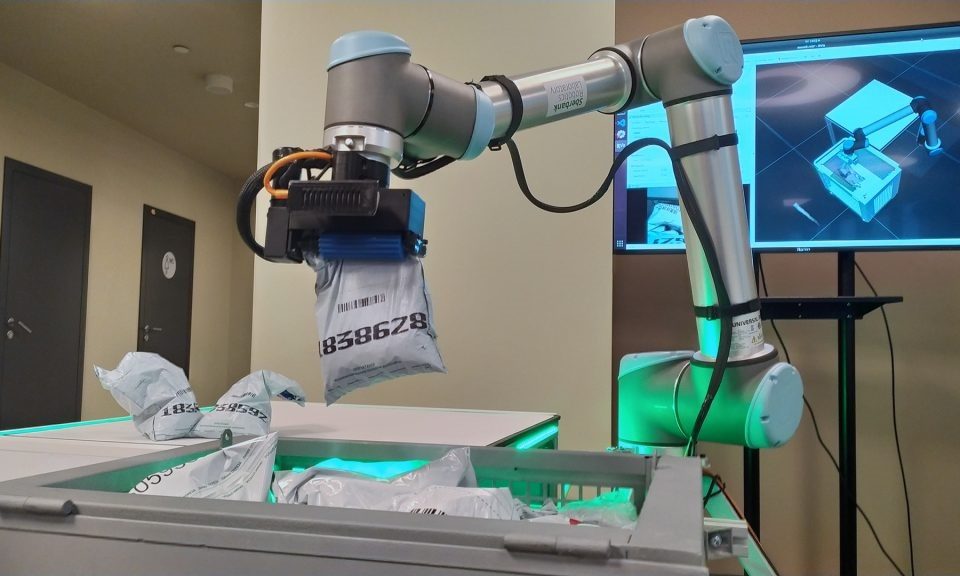
Os pesquisadores de sistemas autônomos da Microsoft colaboraram com cientistas e engenheiros da Sber, uma empresa global de serviços financeiros e tecnologia que opera o SberBank, o maior banco da Rússia, Europa Central e Oriental e uma das principais instituições financeiras em todo o mundo, para usar o aprendizado de reforço para desenvolver tecnologias robóticas para descarregar sacos de coleta de moedas pesadas de carrinhos móveis para serem contadas e reembaladas.
Em um artigo publicado recentemente que descreve esses resultados, os pesquisadores detalham como manipular bolsas de moedas instáveis com um centro de gravidade que muda constantemente é um problema de robótica mais difícil do que agarrar objetos sólidos. É o tipo de cenário comum no mundo físico, mas que os robôs que dependem de sistemas de controle tradicionais ou redes neurais lutam para dominar, disse Albert Efimov, vice-presidente de pesquisa e inovação do SberBank.
‘Vimos uma oportunidade de realmente avançar na ciência e usar o aprendizado por reforço para ensinar uma máquina a realizar um processo muito difícil”, disse Efimov. “A bolsa tem um formato imprevisível e amorfo, e até os humanos precisam pensar por um minuto em como manuseá-la. Para um robô fazer isso é muito importante.”
A equipe Sber e Microsoft usou técnicas de aprendizado por reforço profundo e ensino de máquina para primeiro treinar o agente de IA em um ambiente simulado, onde ele poderia explorar diferentes estratégias e aprender o que funcionava melhor. Uma vez implantado em condições de trabalho do mundo real, o sistema robótico foi capaz de descarregar com sucesso os sacos de moedas na primeira tentativa 95% das vezes.
![]() No Projeto Paidia, pesquisadores do laboratório UK-Cambridge da Microsoft Research estão colaborando com a Ninja Theory, um estúdio de jogos do Xbox. O objetivo é conduzir pesquisas de ponta em aprendizagem por reforço que possam permitir novas aplicações em videogames modernos e desenvolver agentes de IA que possam aprender a colaborar com jogadores humanos.
No Projeto Paidia, pesquisadores do laboratório UK-Cambridge da Microsoft Research estão colaborando com a Ninja Theory, um estúdio de jogos do Xbox. O objetivo é conduzir pesquisas de ponta em aprendizagem por reforço que possam permitir novas aplicações em videogames modernos e desenvolver agentes de IA que possam aprender a colaborar com jogadores humanos.
Os agentes que usam o aprendizado por reforço têm o potencial de antecipar melhor os comportamentos e reagir às nuances para permitir uma colaboração eficaz com jogadores humanos que são criativos e imprevisíveis e têm estilos de jogo diferentes, disse Katja Hofmann, pesquisadora principal que lidera uma equipe que se concentra em reforço de aprendizagem em jogos e outras áreas de aplicação no laboratório Cambridge-UK da Microsoft Research. Os bots desenvolvidos com as tecnologias atuais lutam para navegar por essas complexidades e simplesmente não reagem exatamente da mesma forma que as pessoas.

Videogames como o Bleeding Edge do Ninja Theory, que exige que personagens com diferentes personalidades e superpoderes se unam para marcar pontos e derrotar oponentes, oferecem uma base de teste útil para o desenvolvimento de agentes de IA que podem usar o aprendizado por reforço para coordenar ações e reagir adequadamente a novas situações por meio uma série de recompensas.
“Ter um bot que pode colaborar genuinamente com jogadores humanos é considerado impossível com a tecnologia de IA de jogos tradicional, então isso cria um espaço muito bom para nós”, disse Hofmann. “Se pudermos demonstrar como fazer isso nos jogos, é um primeiro passo para demonstrar como podemos criar agentes fora dos jogos que podem trabalhar em colaboração com os humanos de outras maneiras.”
A equipe de pesquisa do Projeto Paidia e outros em toda a Microsoft ajudaram o Azure Machine Learning a entender o que os heavy users de aprendizado por reforço realmente precisam em termos de infraestrutura e poder de computação.
Eles desenvolveram ferramentas que permitem que as pessoas experimentem a tecnologia, incluindo uma demonstração que permite que as pessoas joguem um jogo simples com um agente de aprendizagem por reforço para ver como ele reage, bem como blocos de notas de amostra do Azure Machine Learning para criar um agente que pode navegar por um labirinto de lava no Minecraft.
Grandes empresas nos campos de serviços industriais, de manufatura e financeiros que empregam cientistas de dados com experiência em aprendizado de reforço estão agora usando as ofertas de aprendizado de reforço do Azure Machine Learning apresentadas no início deste ano para acelerar e gerenciar com eficiência os processos de treinamento na nuvem, disse Keiji Kanazawa, diretor do programa de gerenciador da Microsoft.
“Para os clientes que estão fazendo tentativas e erros em grande escala, o valor da nuvem é que eles podem fazer isso de forma massiva”, disse ele. “Nossas ferramentas permitem que os clientes se concentrem no que estão tentando fazer com o aprendizado por reforço e em seus objetivos e na estrutura das recompensas e todo o cálculo acontece nos bastidores.”
Jennifer Langston escreve sobre pesquisa e inovação da Microsoft. Siga-a no Twitter.




