
O texto neural em fala (Neural TTS) converte o texto em uma voz realista para interfaces mais naturais. Com uma fala em som natural que combina com os padrões de emoção e entonação das vozes humanas, o TTS neural reduz significativamente a fadiga auditiva quando os usuários estão interagindo com os sistemas de IA, permitindo criação de cenários de audiolivros até assistentes de voz.
Voz neural em português do Brasil está disponível
Estamos empolgados em compartilhar que estamos expandindo nossas vozes neurais TTS disponíveis com a Francisca, nossa nova voz em português do Brasil (pt-BR). A Francisca apresenta a mesma prosódia (emprego correto da acentuação tônica das palavras) natural humana das outras vozes neurais do TTS no Azure – Guy (inglês americano masculino), Jessa (inglês americano feminino), Katja (alemão feminino), Elsa (italiana) e Xiaoxiao (mandarim chinesa).
Com um poderoso modelo base, criado utilizando um grande volume de amostras de fala, conseguimos criar a voz da Francisca a partir de menos dados de treinamento do que seria necessário. O modelo de base TTS neural aprende diferentes estilos de fala de vários alto-falantes e, por meio do aprendizado por transferência, pode facilmente adaptar seu estilo ao tipo de alto-falante desejado. Como outras vozes neurais, a Francisca pode gerar ondas de fala realistas para uma determinada entrada de texto, combinando perfeitamente os padrões de transição de emoção e entonação na linguagem falada.
Além da capacidade de sintetizar a fala, os desenvolvedores também podem adaptar a voz para diferentes cenários com diversos estilos de voz usando o TTS neural. Por exemplo, a nova voz pt-BR também pode falar com um tom “alegre”. O estilo “alegre” pode ser usado para expressar uma emoção positiva e feliz. Isso é particularmente útil em cenários de bot de bate-papo. Você pode ajustar os estilos de fala facilmente com o elemento <mstts:express-as> no SSML.
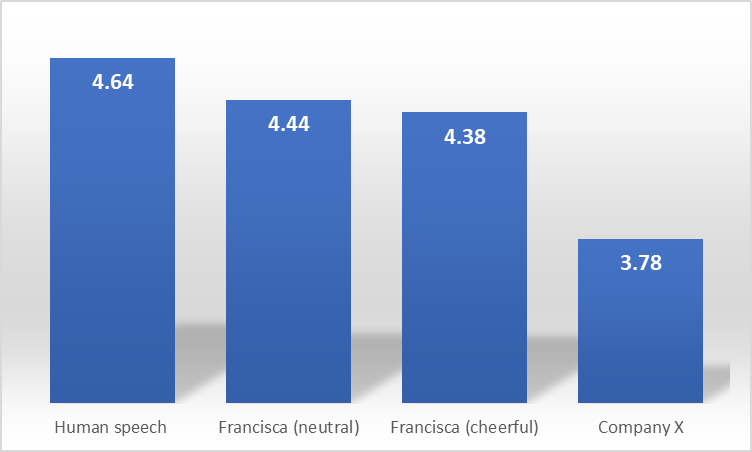
Realizamos estudos de MOS (Mean Opinion Score) para avaliar a naturalidade de Francisca. Em um teste de crowdsourcing com mais de 60 falantes nativos, examinamos 30 áudios produzidos por Francisca no estilo neutro e outros 30 no estilo alegre. As impressões gerais foram classificadas em uma escala Likert de 1 a 5, com naturalidade nas variações de ritmo, variações de afinação, tensões, pausas e inteligibilidade. A fala humana e a voz pt-BR de outro provedor de serviços em nuvem (empresa X) foram usadas como benchmarks. Os resultados mostraram um feedback muito positivo sobre a Francisca nos estilos neutro (4,44) e alegre (4,38).
Figura 1. Comparação MOS de Francisca com fala humana e empresa X
Escute como a Francisca fala:
Alta fidelidade e saída controlável
Como outras vozes neurais, a Francisca foi criada usando uma taxa de amostragem de 24khz. Você pode maximizar a fidelidade das saídas de voz neurais com formatos relacionados a 24khz:
- raw-24khz-16bit-mono-pcm
- riff-24khz-16bit-mono-pcm
- audio-24khz-160kbitrate-mono-mp3
- audio-24khz-96kbitrate-mono-mp3
- audio-24khz-48kbitrate-mono-mp3
Para cenários em que é necessária uma taxa de amostragem mais baixa, como por exemplo reprodução de chamadas telefônicas, a Francisca e outras vozes neurais também podem ser facilmente amostradas com uma taxa de bits mais baixa. Saiba mais sobre o formato de saída suportado.
Ouça o texto em voz alta com o Read Aloud no novo navegador Edge
O Neural TTS está ampliando os serviços da Microsoft. A voz Francisca agora é suportada no novo Microsoft Edge, disponibilizando vozes naturais a qualquer hora e em qualquer lugar.
Figura 2. TTS neural no Edge Read-Aloud
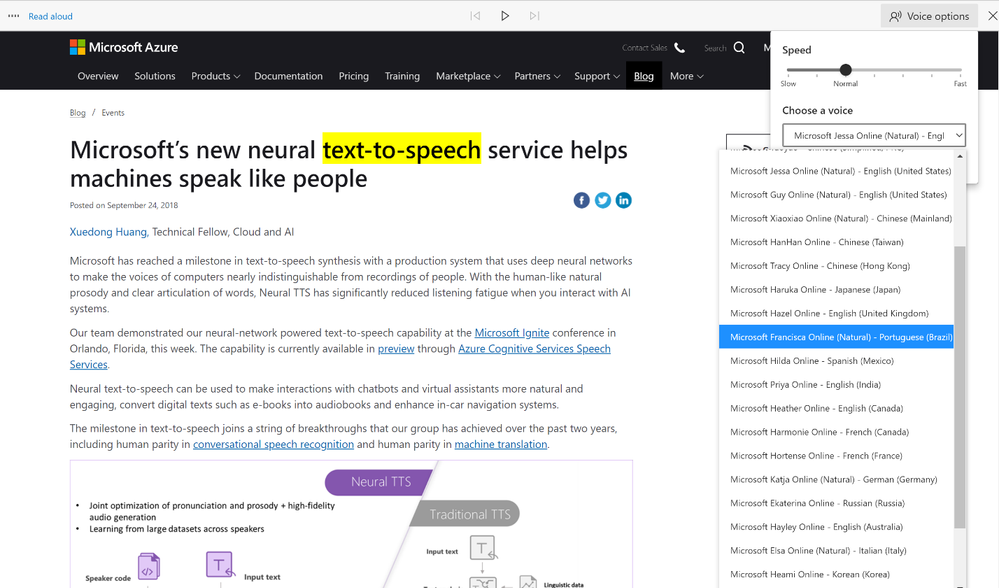
O Edge Read Aloud também facilita o acompanhamento do texto, suportando uma saída com limite de palavras, para que cada palavra que está sendo lida seja destacada simultaneamente na interface do usuário. Esse é um recurso essencial para cenários de leitura imersiva. Para criar seus próprios aplicativos Read Aloud, confira a função SynthesisWordBoundaryEventAsync em nossos códigos de amostra.
Crie uma voz personalizada no português do Brasil
A mesma tecnologia de aprendizado agora é fornecida com o recurso Custom Neural Voice, permitindo que as organizações criem suas vozes digitais únicas com 5X menos dados, enquanto ainda produzem saídas de áudio de alta fidelidade.
Com o português do Brasil (pt-BR) adicionado à família, agora sete localidades são suportadas no portal de treinamento on-line de voz neural personalizada. São elas: inglês americano (en-US), inglês britânico (en-UK), inglês indiano (en-IN), Alemão, francês, chinês (zh-CN) e português do Brasil (pt-BR). Mais localidades estão disponíveis pelo engajamento com o cliente. Envie uma solicitação para criar sua voz personalizada usando a tecnologia TTS neural.
Comece
Com essas atualizações, estamos felizes em oferecer experiências de voz naturais e intuitivas. O Text to Speech possui mais de 75 vozes padrão em mais de 45 idiomas e localidades, além da nossa crescente lista de vozes neurais. Saiba mais sobre como você pode utilizar.


