

Por: Sally Beaty.
A veces, la mejor manera de resolver un problema complejo es tomar una página de un libro para niños. Esa es la lección que los investigadores de Microsoft aprendieron al descubrir cómo empaquetar más fuerza en un paquete mucho más pequeño.
El año pasado, después de pasar su jornada laboral en pensar posibles soluciones a los acertijos del aprendizaje automático, Ronen Eldan, de Microsoft, leía cuentos a su hija antes de dormir cuando pensó: «¿Cómo aprendió esta palabra? ¿Cómo sabe cómo conectar estas palabras?»
Eso llevó al experto en aprendizaje automático de Microsoft Research a preguntarse cuánto podría aprender un modelo de IA a través de solo palabras que un niño de 4 años podría entender y, en última instancia, a un enfoque de entrenamiento innovador que ha producido una nueva clase de modelos de lenguaje pequeños más capaces que promete hacer que la IA sea más accesible para más personas.
Los modelos de lenguaje grandes (LLM, por sus siglas en inglés) han creado nuevas y emocionantes oportunidades para ser más productivos y creativos a través de la IA. Pero su tamaño significa que pueden requerir importantes recursos informáticos para funcionar.
Si bien esos modelos seguirán como el estándar de oro para resolver muchos tipos de tareas complejas, Microsoft ha comenzado a desarrollar una serie de modelos de lenguaje pequeños (SLM, por sus siglas en inglés) que ofrecen muchas de las mismas capacidades que se encuentran en los LLM, pero son más pequeños en tamaño y se entrenan con cantidades más pequeñas de datos.
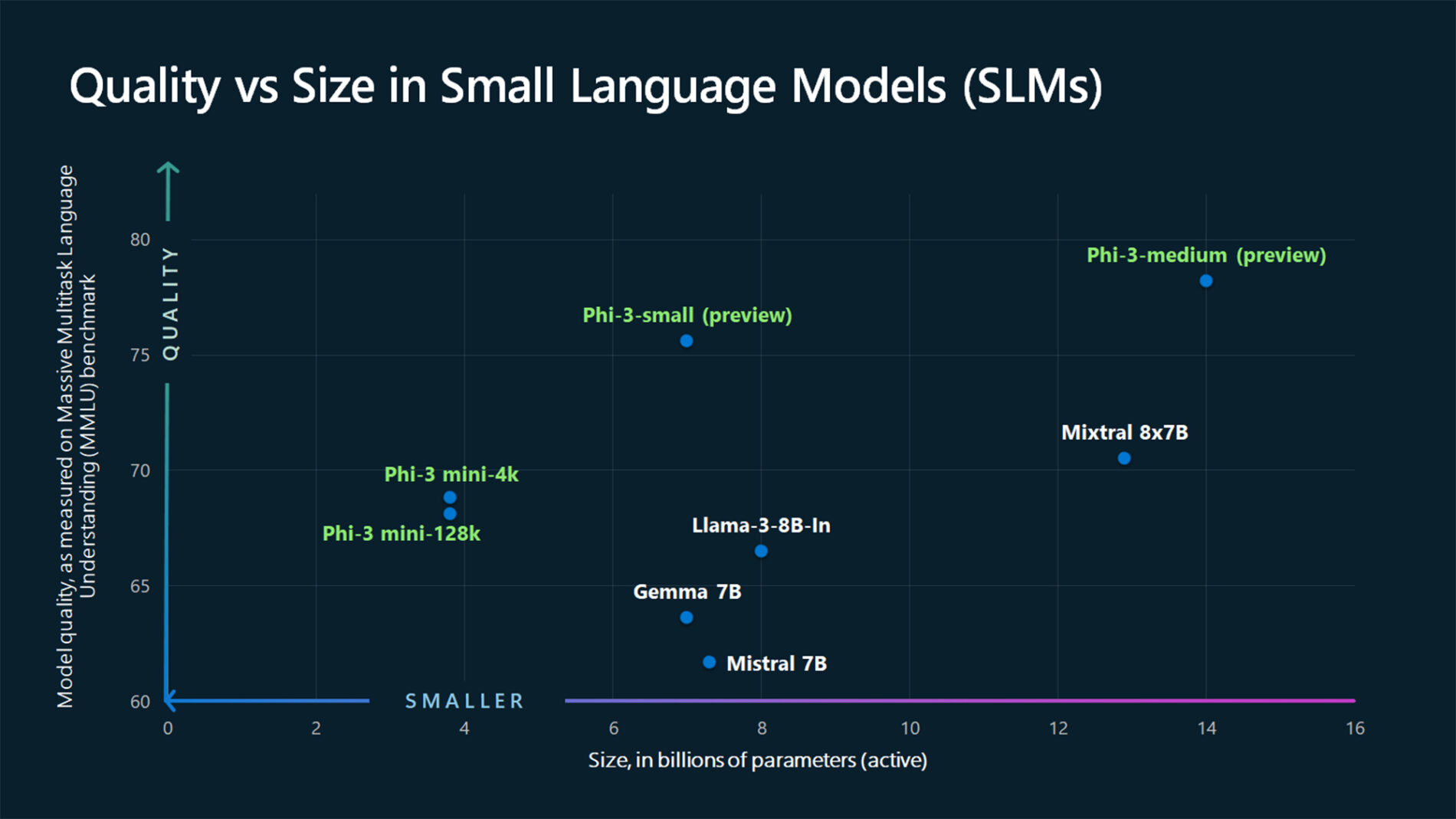
La compañía anunció hoy la familia de modelos abiertos Phi-3, los modelos de lenguaje pequeños más capaces y rentables disponibles. Los modelos Phi-3 superan a los modelos del mismo tamaño y del siguiente tamaño en una variedad de puntos de referencia que evalúan las capacidades de lenguaje, codificación y matemáticas, gracias a las innovaciones de entrenamiento desarrolladas por los investigadores de Microsoft.
Microsoft ahora pone a disposición del público el primero de esa familia de modelos de lenguaje pequeños más potentes: Phi-3-mini, que mide 3.800 millones de parámetros, y que funciona mejor que los modelos que duplican su tamaño, dijo la compañía.
A partir de hoy, estará disponible en el catálogo de modelos de IA de Microsoft Azure y en Hugging Face, una plataforma para modelos de aprendizaje automático, así como en Ollama, un marco ligero para ejecutar modelos en un equipo local.
Microsoft también anunció que pronto llegarán modelos adicionales a la familia Phi-3 para ofrecer más opciones en cuanto a calidad y costo. Phi-3-small (7 mil millones de parámetros) y Phi-3-medium (14 mil millones de parámetros) estarán disponibles en el Catálogo de modelos de Azure AI y otros jardines de modelos en breve.
Los modelos de lenguaje pequeños están diseñados para funcionar bien en tareas más sencillas, son más accesibles y fáciles de usar para organizaciones con recursos limitados y se pueden ajustar con mayor facilidad para satisfacer necesidades específicas.
«Lo que vamos a empezar a ver no es un cambio de lo grande a lo pequeño, sino un cambio de una categoría singular de modelos a una cartera de modelos en la que los clientes tienen la capacidad de tomar una decisión sobre cuál es el mejor modelo para su escenario», dijo Sonali Yadav, gerente principal de productos de IA generativa en Microsoft.
«Es posible que algunos clientes solo necesiten modelos pequeños, otros necesitarán modelos grandes y muchos querrán combinar ambos de diversas maneras», dijo Luis Vargas, vicepresidente de IA de Microsoft.
La elección del modelo de lenguaje adecuado depende de las necesidades específicas de una organización, la complejidad de la tarea y los recursos disponibles. Los modelos de lenguaje pequeños son adecuados para las organizaciones que buscan crear aplicaciones que puedan ejecutarse de manera local en un dispositivo (en lugar de en la nube) y donde una tarea no requiera un razonamiento extenso o se necesite una respuesta rápida.
Los modelos de lenguaje grandes son más adecuados para aplicaciones que necesitan la orquestación de tareas complejas que implican razonamiento avanzado, análisis de datos y comprensión del contexto.
Los modelos de lenguaje pequeños también ofrecen soluciones potenciales para industrias y sectores regulados que se encuentran con situaciones en las que necesitan resultados de alta calidad pero quieren mantener los datos en sus propias instalaciones, dijo Yadav.
Vargas y Yadav están en particular entusiasmados con las oportunidades de colocar SLM más capaces en teléfonos inteligentes y otros dispositivos móviles que operan «en el entorno», no conectados a la nube. (Piensen en las computadoras de los automóviles, las PC sin Wi-Fi, los sistemas de tráfico, los sensores inteligentes en una fábrica, las cámaras remotas o los dispositivos que monitorean el cumplimiento ambiental). Al mantener los datos dentro del dispositivo, los usuarios pueden «minimizar la latencia y maximizar la privacidad», dijo Vargas.
La latencia se refiere al retraso que puede producirse cuando los LLM se comunican con la nube para recuperar la información utilizada para generar respuestas a las indicaciones de los usuarios. En algunos casos, vale la pena esperar respuestas de alta calidad, mientras que en otros escenarios la velocidad es más importante para la satisfacción del usuario.
Debido a que los SLM pueden funcionar sin conexión, más personas podrán poner la IA a trabajar de maneras que antes no eran posibles, dijo Vargas.
Por ejemplo, los SLM también podrían utilizarse en zonas rurales que carecen de servicio celular. Pensemos en un agricultor que inspecciona los cultivos y encuentra signos de enfermedad en una hoja o rama. A través de un SLM con capacidad visual, el agricultor podría tomar una fotografía del cultivo en cuestión y obtener recomendaciones inmediatas sobre cómo tratar plagas o enfermedades.
«Si estás en una parte del mundo que no tiene una buena red», dijo Vargas, «aún podrás tener experiencias de IA en tu dispositivo».
El papel de los datos de alta calidad
Tal como su nombre lo indica, en comparación con los LLM, los SLM son pequeños, al menos para los estándares de IA. Phi-3-mini tiene «sólo» 3.800 millones de parámetros, una unidad de medida que se refiere a las perillas algorítmicas de un modelo que ayudan a determinar su salida. Por el contrario, los modelos de lenguaje grande de mayor tamaño, son muchos órdenes de magnitud más grandes.
Se pensaba que los enormes avances en IA generativa introducidos por los grandes modelos de lenguaje eran posibles en gran medida por su gran tamaño. Sin embargo, el equipo de Microsoft fue capaz de desarrollar modelos de lenguaje pequeños que pueden ofrecer resultados de gran tamaño en un paquete pequeño. Este avance fue posible gracias a un enfoque con una alta selección de los datos de entrenamiento, que es donde entran en juego los libros infantiles.
Hasta la fecha, la forma estándar de entrenar grandes modelos de lenguaje ha sido usar cantidades masivas de datos de Internet. Se pensó que esta era la única forma de satisfacer el enorme apetito de este tipo de modelo por el contenido, que necesita «aprender» para comprender los matices del lenguaje y generar respuestas inteligentes a las indicaciones del usuario. Pero los investigadores de Microsoft tenían una idea diferente.
«En lugar de entrenar solo con datos web sin procesar, ¿por qué no buscar datos que sean de muy alta calidad?», preguntó Sebastien Bubeck, vicepresidente de investigación de IA generativa de Microsoft, quien ha liderado los esfuerzos de la compañía para desarrollar modelos de lenguaje pequeños más capaces. Pero, ¿dónde enfocarse?
Inspirados por el ritual de lectura nocturna de Eldan con su hija, los investigadores de Microsoft decidieron crear un conjunto de datos discreto a partir de 3.000 palabras, incluido un número casi igual de sustantivos, verbos y adjetivos. A continuación, pidieron a un modelo lingüístico grande que creara un cuento infantil con un sustantivo, un verbo y un adjetivo de la lista, un prompt que repitieron millones de veces durante varios días, lo que generó millones de cuentos infantiles diminutos.
Llamaron al conjunto de datos resultante «TinyStories» y lo utilizaron para entrenar modelos de lenguaje muy pequeños de alrededor de 10 millones de parámetros. Para su sorpresa, cuando se les pidió que crearan sus propias historias, el modelo de lenguaje pequeño entrenado en TinyStories generó narrativas fluidas con una gramática perfecta.
A continuación, llevaron su experimento a un nivel superior, por así decirlo. Esta vez, un grupo más grande de investigadores utilizó datos seleccionados de manera cuidados y disponibles a nivel público, que se filtraron en función del valor educativo y la calidad del contenido para entrenar Phi-1. Después de recopilar información disponible de manera general en un conjunto de datos inicial, utilizaron una fórmula de solicitud y propagación inspirada en la utilizada para TinyStories, pero la llevaron un paso más allá y la hicieron más sofisticada, para que capturara un alcance más amplio de datos. Para garantizar una alta calidad, filtraron de manera repetida el contenido resultante antes de volver a introducirlo en un LLM para su posterior síntesis. De esta manera, durante varias semanas, construyeron un corpus de datos lo suficientemente grande como para entrenar un SLM más capaz.
«Se pone mucho cuidado en la producción de estos datos sintéticos», dijo Bubeck, refiriéndose a los datos generados por la IA, «revisándolos, asegurándose de que tengan sentido, filtrándolos. No tomamos todo lo que producimos». Llamaron a este conjunto de datos «CodeTextbook».
Los investigadores mejoraron aún más el conjunto de datos al abordar la selección de datos como un maestro que desglosa conceptos difíciles para un estudiante. «Debido a que se trata de leer material similar a un libro de texto, de documentos de calidad que explican las cosas muy, muy bien», dijo Bubeck, «hace que la tarea del modelo lingüístico de leer y comprender este material sea mucho más fácil».
Distinguir entre información de alta y baja calidad no es difícil para un humano, pero clasificar más de un terabyte de datos que los investigadores de Microsoft determinaron que necesitarían para entrenar su SLM sería imposible sin la ayuda de un LLM.
«El poder de la generación actual de grandes modelos de lenguaje es realmente un facilitador que no teníamos antes en términos de generación de datos sintéticos», dijo Ece Kamar, vicepresidente de Microsoft que dirige el Microsoft Research AI Frontiers Lab, donde se desarrolló el nuevo enfoque de entrenamiento.
Comenzar con datos seleccionados de manera cuidadosa ayuda a reducir la probabilidad de que los modelos devuelvan respuestas no deseadas o inapropiadas, pero no es suficiente para protegerse contra todos los posibles desafíos de seguridad. Al igual que con todos los lanzamientos de modelos de IA generativa, los equipos de productos y de IA responsables de Microsoft utilizaron un enfoque de varias capas para administrar y mitigar los riesgos en el desarrollo de modelos Phi-3.
Por ejemplo, después de la capacitación inicial, proporcionaron ejemplos adicionales y comentarios sobre cómo deberían responder de manera ideal los modelos, lo que incorpora una capa de seguridad adicional y ayuda al modelo a generar resultados de alta calidad. Cada modelo también se somete a evaluación, pruebas y red-teaming manual, en el que los expertos identifican y abordan posibles vulnerabilidades.
Por último, los desarrolladores que usan la familia de modelos Phi-3 también pueden aprovechar un conjunto de herramientas disponibles en Azure AI para ayudarles a crear aplicaciones más seguras y confiables.
Elegir el modelo de lenguaje del tamaño adecuado para la tarea adecuada
Pero incluso los modelos de lenguaje pequeños entrenados con datos de alta calidad tienen limitaciones. No están diseñados para la recuperación de conocimientos en profundidad, donde los modelos de lenguaje grandes sobresalen debido a su mayor capacidad y entrenamiento a través de conjuntos de datos mucho más grandes.
Los LLM son mejores que los SLM en el razonamiento complejo sobre grandes cantidades de información debido a su tamaño y potencia de procesamiento. Esa es una función que podría ser relevante para el descubrimiento de fármacos, por ejemplo, al ayudar a estudiar de manera minuciosa vastos almacenes de artículos científicos, analizar patrones complejos y comprender las interacciones entre genes, proteínas o sustancias químicas.
«Cualquier cosa que implique cosas como la planificación de dónde tienes una tarea, y la tarea es lo suficientemente complicada como para que necesites descubrir cómo dividir esa tarea en un conjunto de subtareas, y a veces sub-subtareas, y luego ejecutarlas a través de todas ellas para llegar a una respuesta final… realmente van a estar en el dominio de los modelos grandes por un tiempo», dijo Vargas.
Basándose en las conversaciones en curso con los clientes, Vargas y Yadav esperan que algunas empresas «descarguen» algunas tareas a modelos pequeños si la tarea no es demasiado compleja.

Por ejemplo, una empresa podría utilizar Phi-3 para resumir los puntos principales de un documento largo o extraer información relevante y tendencias del sector a partir de informes de investigación de mercado. Otra organización podría usar Phi-3 para generar textos, lo que ayudaría a crear contenido para equipos de marketing o ventas, como descripciones de productos o publicaciones en redes sociales. O bien, una empresa podría usar Phi-3 para impulsar un chatbot de soporte para responder a las preguntas básicas de los clientes sobre su plan o actualizaciones de servicio.
A nivel interno, Microsoft ya ha comenzado a utilizar conjuntos de modelos, donde los modelos de lenguaje grandes desempeñan el papel de enrutador, para dirigir ciertas consultas que requieren menos potencia de cálculo a modelos de lenguaje pequeños, mientras aborda otras solicitudes más complejas por sí mismo.
«La afirmación aquí no es que los SLM vayan a sustituir o reemplazar a los modelos de lenguaje grande», dijo Kamar. En cambio, los SLM «están en una posición única para la computación en el entorno, la computación en el dispositivo, cálculos en los que no es necesario ir a la nube para hacer las cosas. Por eso es importante para nosotros entender las fortalezas y debilidades de este portafolio modelo».
Y el tamaño conlleva importantes ventajas. Todavía hay una brecha entre los modelos de lenguaje pequeños y el nivel de inteligencia que se puede obtener de los modelos grandes en la nube, dijo Bubeck. «Y tal vez siempre haya una brecha porque, ya sabes, los grandes modelos van a seguir su progreso».
Enlaces relacionados:
- Más información: Azure AI
- Leer más: Informe técnico de Phi-3: Un modelo de lenguaje altamente capaz localmente en su teléfono
Imagen de portada: Sebastien Bubeck, vicepresidente de investigación de IA generativa de Microsoft, que ha liderado los esfuerzos de la empresa para desarrollar modelos de lenguaje pequeño más capaces. (Foto de Dan DeLong para Microsoft)