

Por: Blake Bullwinkel, investigador de seguridad de IA.
Por: Ram Shankar Siva Kumar, vaquero de datos, equipo rojo de IA.
El equipo rojo de IA de Microsoft se complace en compartir nuestro documento técnico, «Lecciones de aplicar acciones de equipo rojo 100 productos de IA generativa«.
El equipo rojo de IA se formó en 2018 para abordar el creciente panorama de los riesgos de seguridad y protección de la IA. Desde entonces, hemos ampliado de manera significativa el alcance y la escala de nuestro trabajo. Somos uno de los primeros equipos rojos de la industria que cubre tanto la seguridad como la IA responsable, y realizar acciones de equipo rojo (red teaming) se ha convertido en una parte clave del enfoque de Microsoft para el desarrollo de productos de IA generativa. El trabajo en equipo rojo es el primer paso para identificar daños potenciales y es seguido por importantes iniciativas en la empresa para medir, gestionar y gobernar el riesgo de IA para nuestros clientes. El año pasado, también anunciamos PyRIT (The Python Risk Identification Tool for generative AI), un conjunto de herramientas de código abierto para ayudar a los investigadores a identificar vulnerabilidades en sus propios sistemas de IA.
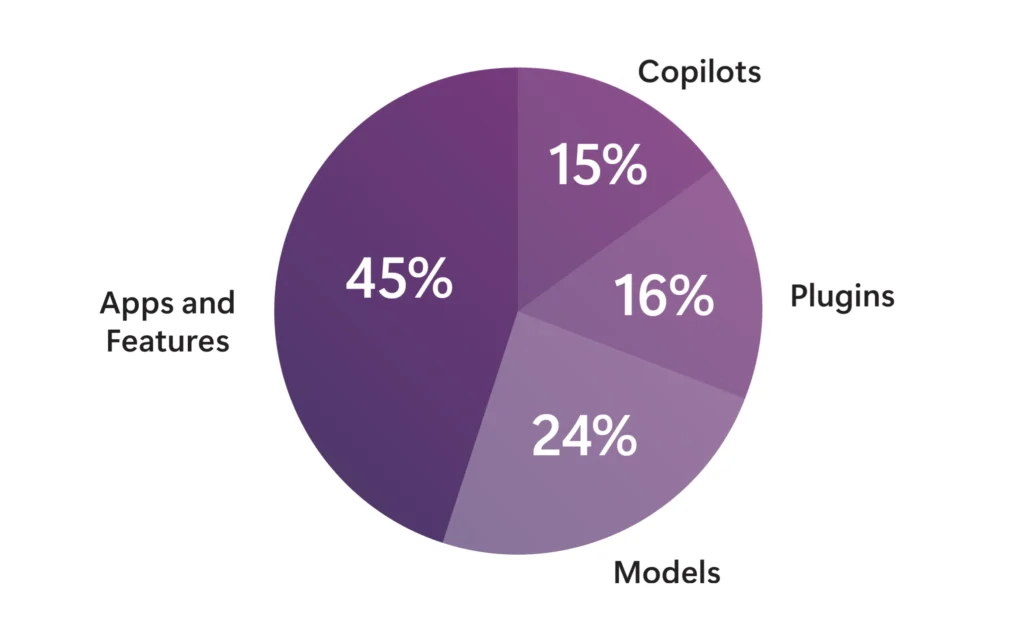
Con un enfoque en nuestra misión ampliada, ahora hemos creado un equipo rojo de más de 100 productos de IA generativa. El documento técnico que publicamos ahora proporciona más detalles sobre nuestro enfoque del equipo rojo de IA e incluye los siguientes aspectos destacados:
- Nuestra ontología de equipo rojo de IA, que utilizamos para modelar los componentes principales de un ciberataque, incluidos los actores adversarios o benignos, los TTP (Tácticas, Técnicas y Procedimientos), las debilidades del sistema y los impactos posteriores. Esta ontología proporciona una forma coherente de interpretar y diseminar una amplia gama de hallazgos de seguridad y protección.
- Ocho lecciones principales aprendidas de nuestra experiencia en la creación de equipos de más de 100 productos de IA generativa. Estas lecciones están dirigidas a los profesionales de la seguridad que buscan identificar riesgos en sus propios sistemas de IA y arrojan luz sobre cómo alinear los esfuerzos de equipo rojo con los daños potenciales en el mundo real.
- Cinco estudios de caso de nuestras operaciones, que destacan la amplia gama de vulnerabilidades que buscamos, incluida la seguridad tradicional, la IA responsable y los daños psicosociales. Cada caso de estudio demuestra cómo se utiliza nuestra ontología para capturar los componentes principales de un ataque o vulnerabilidad del sistema.
El equipo rojo de IA de Microsoft aborda una multitud de escenarios
A lo largo de los años, el equipo rojo de IA ha abordado una amplia variedad de escenarios con los que tal vez también se hayan encontrado otras organizaciones. Nos centramos en las vulnerabilidades que tienen más probabilidades de causar daño en el mundo real, y nuestro documento técnico comparte estudios de casos de nuestras operaciones que destacan cómo lo hemos hecho en cuatro escenarios, incluida la seguridad, la IA responsable, las capacidades peligrosas (como la capacidad de un modelo para generar contenido peligroso) y los daños psicosociales. Como resultado, somos capaces de reconocer una variedad de posibles amenazas cibernéticas y adaptarnos con rapidez cuando nos enfrentamos a otras nuevas.
Esta misión le ha dado a nuestro equipo rojo una amplia gama de experiencias para enfrentar con habilidad los riesgos, sin importar:
- Tipo de sistema, incluido Microsoft Copilot, modelos integrados en sistemas y modelos de código abierto.
- Modalidad, ya sea de texto a texto, de texto a imagen o de texto a vídeo.
- Tipo de usuario: el riesgo del usuario empresarial, por ejemplo, es diferente de los riesgos del consumidor y requiere un enfoque único de acciones de equipo rojo. Las audiencias de nicho, como las de una industria específica como la atención médica, también merecen un enfoque matizado.
Las tres principales conclusiones del documento técnico
El equipo rojo de IA es una práctica para sondear la seguridad de los sistemas de IA generativa. En pocas palabras, «rompemos» la tecnología para que otros puedan reconstruirla más fuerte. Años de aplicar acciones de equipo rojo nos han dado una visión invaluable de las estrategias más efectivas. Al reflexionar sobre las ocho lecciones discutidas en el documento técnico, podemos destilar tres puntos principales que los líderes empresariales deben saber.
Conclusión 1: Los sistemas de IA generativa amplifican los riesgos de seguridad existentes e introducen otros nuevos
La integración de modelos de IA generativa en aplicaciones modernas ha introducido nuevos vectores de ciberataque. Sin embargo, muchas discusiones en torno a la seguridad de la IA pasan por alto las vulnerabilidades existentes. Los equipos rojos de IA deben prestar atención a los vectores de ciberataque, tanto antiguos como nuevos.
- Riesgos de seguridad existentes: Los riesgos de seguridad de las aplicaciones a menudo se derivan de prácticas de ingeniería de seguridad inadecuadas, incluidas dependencias obsoletas, manejo inadecuado de errores, credenciales en el origen, falta de saneamiento de entrada y salida y cifrado de paquetes inseguro. Uno de los casos de estudio de nuestro documento técnico describe cómo un componente FFmpeg obsoleto en una aplicación de IA de procesamiento de video introdujo una vulnerabilidad de seguridad conocida llamada falsificación de solicitudes del lado del servidor (SSRF), que podría permitir a un adversario escalar los privilegios de su sistema.

- Debilidades a nivel de modelo: Los modelos de IA han ampliado la superficie de ciberataque mediante la introducción de nuevas vulnerabilidades. Las inyecciones rápidas, por ejemplo, explotan el hecho de que los modelos de IA a menudo tienen dificultades para distinguir entre las instrucciones a nivel de sistema y los datos del usuario. Nuestro documento técnico incluye un estudio de caso de acciones de equipo rojo sobre cómo utilizamos las inyecciones rápidas para engañar a un modelo de lenguaje de visión.
Consejo del equipo rojo: Los equipos rojos de IA deben estar atentos a los nuevos vectores de ciberataque mientras permanecen atentos a los riesgos de seguridad existentes. Las mejores prácticas de seguridad de la IA deben incluir una higiene cibernética básica.
Conclusión 2: Los humanos están en el centro de la mejora y la seguridad de la IA
Si bien las herramientas de automatización son útiles para crear avisos, orquestar ciberataques y calificar respuestas, las acciones de equipo rojo no se puede automatizar por completo. Las acciones de equipo rojo de IA dependen en gran medida de la experiencia humana.
Los seres humanos son importantes por varias razones, entre ellas:
- Experiencia en la materia: los LLM son capaces de evaluar si la respuesta de un modelo de IA contiene discurso de odio o contenido sexual explícito, pero no son tan fiables a la hora de evaluar el contenido en áreas especializadas como la medicina, la ciberseguridad y la CBRN (química, biológica, radiológica y nuclear). Estas áreas requieren expertos en la materia que puedan evaluar el riesgo del contenido para los equipos rojos de IA.
- Competencia cultural: Los modelos de lenguaje moderno utilizan de manera principal datos de entrenamiento en inglés, puntos de referencia de rendimiento y evaluaciones de seguridad. Sin embargo, a medida que los modelos de IA se despliegan en todo el mundo, es crucial diseñar sondas de equipo rojo que no solo tengan en cuenta las diferencias lingüísticas, sino que también redefinan los daños en diferentes contextos políticos y culturales. Estos métodos solo pueden desarrollarse a través del esfuerzo colaborativo de personas con diversos antecedentes culturales y experiencia.
- Inteligencia emocional: En algunos casos, se requiere inteligencia emocional para evaluar los resultados de los modelos de IA. Uno de los estudios de caso de nuestro documento técnico analiza cómo investigamos los daños psicosociales mediante la investigación de cómo responden los chatbots a los usuarios en apuros. En última instancia, solo los humanos pueden evaluar por completo la gama de interacciones que los usuarios pueden tener con los sistemas de IA en la naturaleza.
Consejo del equipo rojo: Adopten herramientas como PyRIT para ampliar las operaciones, pero mantengan a los humanos en el circuito de equipo rojo para tener el mayor éxito en la identificación de vulnerabilidades impactantes de seguridad y protección de la IA.
Conclusión 3: La defensa en profundidad es clave para mantener seguros los sistemas de IA
Se han desarrollado numerosas mitigaciones para abordar los riesgos de seguridad que plantean los sistemas de IA. Sin embargo, es importante recordar que las mitigaciones no eliminan el riesgo por completo. En última instancia, aplicar acciones de equipo rojo de IA es un proceso continuo que debe adaptarse a la rápida evolución del panorama de riesgos y tener como objetivo aumentar el coste de atacar con éxito un sistema tanto como sea posible.
- Nuevas categorías de daño: A medida que los sistemas de IA se vuelven más sofisticados, a menudo introducen categorías de daño nuevas. Por ejemplo, uno de nuestros estudios de caso explica cómo probamos un LLM de última generación en busca de capacidades persuasivas riesgosas. Los equipos rojos de IA deben actualizar de manera constante sus prácticas para anticipar y sondear estos nuevos riesgos.
- Economía de la ciberseguridad: Todos los sistemas son vulnerables porque los humanos son falibles y los adversarios son persistentes. Sin embargo, pueden disuadir a los adversarios a través de aumentar el costo de atacar un sistema más allá del valor que se obtendría. Una forma de aumentar el coste de los ciberataques es mediante el uso de ciclos de reparación de averías.1 Esto implica llevar a cabo múltiples rondas de acciones de equipo rojo, medición y mitigación, a veces denominadas «purple teaming», para fortalecer el sistema para manejar una variedad de ataques.
- Acción del gobierno: La acción de la industria para defenderse contra los ciberatacantes y los fracasos es una cara de la moneda de la seguridad de la IA. El otro lado es la acción del gobierno de una manera que podría disuadir y desalentar estos fracasos más amplios. Tanto el sector público como el privado deben demostrar compromiso y vigilancia, para garantizar que los ciberatacantes ya no tengan la sartén por el mango y que la sociedad en general pueda beneficiarse de los sistemas de IA que son seguros de manera inherente.
Consejo del equipo rojo: Actualicen de manera continua sus prácticas para tener en cuenta los daños novedosos, utilicen ciclos de reparación de averías para que los sistemas de IA sean lo más seguros posible e inviertan en técnicas sólidas de medición y mitigación.
Mejoren su experiencia en equipos rojos de IA
El documento técnico «Lessons From Red Teaming 100 Generative AI Products» incluye nuestra ontología de equipo rojo de IA, lecciones aprendidas adicionales y cinco estudios de casos de nuestras operaciones. Esperamos que el artículo y la ontología les resulten útiles para organizar sus propios ejercicios de red teaming de IA y desarrollar más estudios de casos para aprovechar las ventajas de PyRIT, nuestro marco de automatización de código abierto.
Juntos, la comunidad de ciberseguridad puede refinar sus enfoques y compartir las mejores prácticas para abordar de manera efectiva los desafíos que se avecinan. Descarguen nuestro documento técnico de acciones de equipo rojo para obtener más información sobre lo que hemos aprendido. A medida que avanzamos en nuestro propio recorrido de aprendizaje continuo, agradeceríamos sus comentarios y escuchar sobre sus propias experiencias de equipo rojo de IA.
Más información de Microsoft Security
Para obtener más información sobre las soluciones de seguridad de Microsoft, visiten nuestro sitio web. Agreguen a Favoritos el blog de Seguridad para mantenerse al día con nuestra cobertura experta en asuntos de seguridad. Además, síganos en LinkedIn (Microsoft Security) y X (@MSFTSecurity) para conocer las últimas noticias y actualizaciones sobre ciberseguridad.
¹ Phi-3 Safety Post-Training: Alineando Modelos de Lenguaje con un Ciclo de «Break-Fix»