 written by
written byAllison Linn
t Microsoft’s research labs around the world, computer scientists, programmers, engineers and other experts are trying to crack some of the computer industry’s toughest problems, from system design and security to quantum computing and data visualization.
A subset of those scientists, engineers and programmers have a different goal: They’re trying to use computer science to solve one of the most complex and deadly challenges humans face: Cancer.
And, for the most part, they are doing so with algorithms and computers instead of test tubes and beakers.
“We are trying to change the way research is done on a daily basis in biology,” said Jasmin Fisher, a biologist by training who works in the programming principles and tools group in Microsoft’s Cambridge, U.K., lab.
One team of researchers is using machine learning and natural language processing to help the world’s leading oncologists figure out the most effective, individualized cancer treatment for their patients, by providing an intuitive way to sort through all the research data available.
Another is pairing machine learning with computer vision to give radiologists a more detailed understanding of how their patients’ tumors are progressing.
Yet another group of researchers has created powerful algorithms that help scientists understand how cancers develop and what treatments will work best to fight them.
And another team is working on moonshot efforts that could one day allow scientists to program cells to fight diseases, including cancer.
Two core computer science approaches
Although the individual projects vary widely, Microsoft’s overarching philosophy toward solving cancer focuses on two basic approaches, said Jeannette M. Wing, Microsoft’s corporate vice president in charge of the company’s basic research labs.
One approach is rooted in the idea that cancer and other biological processes are information processing systems. Using that approach the tools that are used to model and reason about computational processes – such as programming languages, compilers and model checkers – are used to model and reason about biological processes.
The other approach is more data-driven. It’s based on the idea that researchers can apply techniques such as machine learning to the plethora of biological data that has suddenly become available, and use those sophisticated analysis tools to better understand and treat cancer.
Both approaches share some common ground – including the core philosophy that success depends on both biologists and computer scientists bringing their expertise to the problem.
“The collaboration between biologists and computer scientists is actually key to making this work,” Wing said.
Wing said Microsoft has good reason to make broad, bold investments in using computer science to tackle cancer. For one, it’s in keeping with the company’s core mission.
“If you talk about empowering every person and organization to achieve more, this is step one in that journey,” she said.
Beyond that, she said, Microsoft’s extensive investment in cloud computing is a natural fit for a field that needs plenty of computing power to solve big problems.
Longer term, she said, it makes sense for Microsoft to invest in ways it can provide tools to customers no matter what computing platform they choose – even if, one day, that platform is a living cell.
“If the computers of the future are not going to be made just in silicon but might be made in living matter, it behooves us to make sure we understand what it means to program on those computers,” she said.
Organizing knowledge to find better treatment
The research teams’ efforts also come amid major breakthroughs in understanding the role genetics plays in both getting and treating cancer. That, in turn, is spurring an even stronger focus on treating each cancer case in a personalized way, sometimes called precision medicine.
“We’re in a revolution with respect to cancer treatment,” said David Heckerman, a distinguished scientist and senior director of the genomics group at Microsoft. “Even 10 years ago people thought that you treat the tissue: You have brain cancer, you get brain cancer treatment. You have lung cancer, you get lung cancer treatment. Now, we know it’s just as, if not more, important to treat the genomics of the cancer, e.g. which genes have gone bad in the genome.”
That research has been helped along by recent advances in the ability to more easily and affordably map the human genome and other genetic material. That’s giving scientists a wealth of information for understanding cancer and developing more personalized and effective treatments – but the sheer amount of data also presents plenty of challenges.
“We’ve reached the point where we are drowning in information. We can measure so much, and because we can, we do,” Fisher said. “How do you take that information and turn that into knowledge? That’s a different story. There’s a huge leap here between information and data, and knowledge and understanding.”
Researchers say that’s an area where computer scientists can best help the biological sciences. Some of the most promising approaches involve using a branch of artificial intelligence called machine learning to automatically do the legwork that can make precision medicine unwieldy.
In a more basic scenario, a machine learning system can do things like identify a cat in a photo based on previous pictures of cats it has seen. In the field of cancer research, these techniques are being deployed to sort and organize millions of pieces of research and medical data.
“These are our fortes, artificial intelligence and machine learning,” said Hoifung Poon, a researcher in Microsoft’s Redmond, Washington, lab who is using a technique called machine reading to help oncologists find the latest information about effective cancer treatments for individual patients.
Another big advantage: cloud computing. Using tools like the Azure cloud computing platform, researchers are able to provide biologists with these kinds of approaches even if the medical experts don’t have their own powerful computers, by hosting the tools in the cloud for anyone to access over the internet.
Microsoft researchers say the company also is well-positioned to lead computing cancer efforts because of its long history as a software company providing a platform other people can build from and expand on.
We’re in a revolution with respect to cancer treatment- David Heckerman, Microsoft
“If you look at the combination of things that Microsoft does really well, then it makes perfect sense for Microsoft to be in this industry,” said Andrew Phillips, who heads the biological computation research group at Microsoft’s Cambridge, U.K., lab.
In his field specifically, Phillips said researchers benefit from Microsoft’s history as a software innovator.
“We can use methods that we’ve developed for programming computers to program biology, and then unlock even more applications and even better treatments,” he said.
Of course, none of these tools will help fight cancer and save lives unless they are accessible and understandable to biologists, oncologists and other cancer researchers.
Microsoft researchers say they have taken great pains to make their systems easy to use, even for people without any background – or particular interest – in technology and computer science. That includes everything from learning to speak the language of doctors and biologists to designing computer-based tools that mimic the systems people use in their labs.
“We are always talking about building tools that help the doctors,” said Aditya Nori, a senior researcher who specializes in programming languages and machine learning and is working on systems to assess tumor changes.
asmin Fisher doesn’t want to cure cancer. She wants to solve it — and she believes it’s possible in her lifetime.
“I’m not saying that cancer will cease to exist,” said Fisher, a senior researcher in the programming principles and tools group in Microsoft’s Cambridge, U.K., research lab and an associate professor in the biochemistry department at Cambridge University. “But once you manage it – once you know how to control it – it’s a solved problem.”
To do that, Fisher and her team believe you need to use technology to understand cancer – or, more specifically, the biological processes that cause a cell to turn cancerous. Then, once you understand where the problem occurred, you need to figure out how to fix it.
Fisher takes the computational approach to cancer research. She thinks of it like computer scientists think about computer programs. Her goal is to understand the program, or set of instructions, that causes a cell to execute its commands, or behave in a certain way. Once you can build a computer program that describes the healthy behavior of a cell, and compare it to that of a diseased cell, you can figure out a way that the unhealthy behavior can be fixed.
“If you can figure out how to build these programs, and then you can debug them, it’s a solved problem,” she said.
Bio Model Analyzer
That sounds simple enough – but, of course, actually getting there is quite complicated.
One approach Fisher and her team are taking is called Bio Model Analyzer, or BMA for short. It’s a cloud-based tool that allows biologists to model how cells interact and communicate with each other, and the connections they make.
The system creates a computerized model that compares the biological processes of a healthy cell with the abnormal processes that occur when disease strikes. That, in turn, could allow scientists to see the interactions between the millions of genes and proteins in the human body that lead to cancer, and to quickly devise the best, least harmful way to provide personalized treatment for that patient.
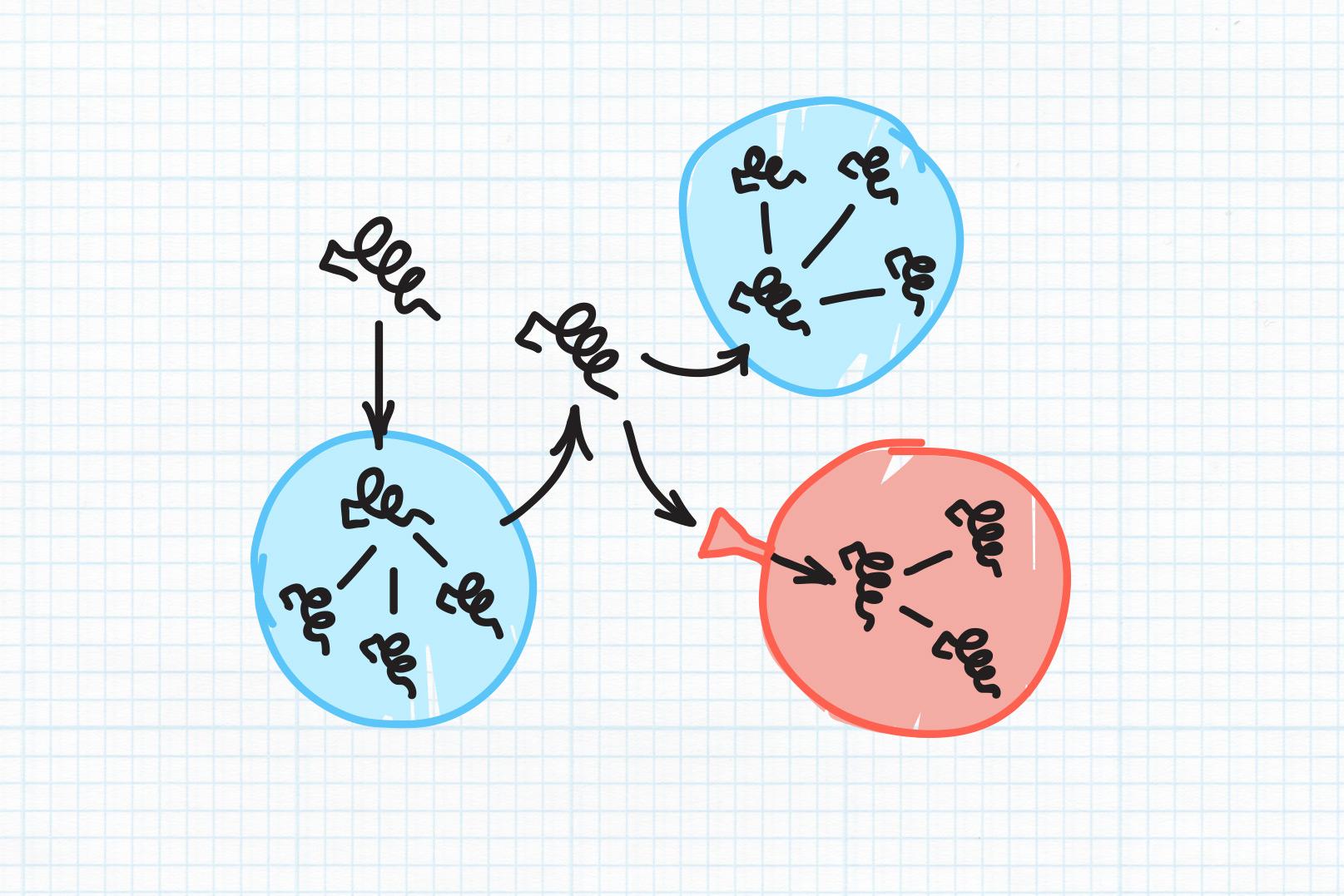
“I use BMA to understand cancers – understand the process of becoming cancers, understand the communications that are going on,” said Ben Hall, a Royal Society University Research Fellow in Cambridge, U.K., who works with Fisher on the project.
Hall said BMA has many uses, including figuring out how to detect cancer earlier and understanding how better to treat cancer by modeling which medicines will be most effective and at what point the cancer might become resistant to them.
Here’s one way BMA might work: Let’s say a patient has a rare and often fatal form of brain cancer. Using BMA, clinicians could enter all the biological information about that patient into the system. Then, they could use the system to run all sorts of experiments, comparing the cancer patient’s information with that of a healthy patient, for example, or simulating how the patient’s system might respond to various medications.
That kind of computation would be impossible for a person to do using pen and paper, or even a simpler computer program, because there are so many variables within the millions of molecules, proteins and genes that are working together in the human body. To create the kinds of solutions that Fisher envisions, you need powerful computational models that are capable of building these immensely complex models and running through possible solutions for abnormalities.
The ability to run these types of experiments “in silico” – or using computers – instead of with pen and paper or test tube and beaker also allows the researchers to quickly test many more possibilities. That, in turn, is giving them a better understanding about how cancers develop, evolve and interact with the rest of the body.
“I think it will accelerate research because we are able to test so many more possibilities than we possibly could in the laboratory,” said Jonathan Dry, a principal scientist at the pharmaceutical company AstraZeneca whose team collaborated with Fisher’s team.
In the past, Dry said, the sheer difficulty of testing any hypothesis meant that researchers had to focus on their favorite ones, making educated guesses as to what might be most promising. A system such as BMA allows them to try out all sorts of ideas, which makes it more likely they will hit on the correct ones – and less likely they’ll miss the dark horse candidates.
“If we had to go in and experimentally test each hypothesis, it would be nigh on impossible,” Dry said. “These models give us a sense, really, of all the possibilities.”
Improving and personalizing cancer treatment
Microsoft and AstraZeneca have been using BMA to better understand drug interactions and resistance in patients with a certain type of leukemia. With BMA, the two research teams were able to better understand why various patients responded differently to certain treatments.
Dry said BMA holds huge promise for more personalized approaches to cancer treatment, or precision medicine. The researchers are hoping that a system like BMA could eventually allow researchers and oncologists to look in detail at a person’s cancer case and also run tests that consider other factors that could impact treatment, such as whether the patient has another illness or is taking non-cancer medications that might interact with the cancer drugs.

“It really recognizes that every patient is an individual and there can be vast heterogeneity,” Dry said.
A computer science system that makes sense to a biologist
Fisher believes that systems such as BMA have the possibility to revolutionize how cancer is understood, but success is only possible if the biologists feel comfortable using them.
David Benque, a designer who has worked extensively on BMA, said the system was built to be as familiar and understandable to biologists as possible. Benque worked for years to create tools that visually mimic what scientists might use in a lab, using language biologists could understand.
Fisher said it’s imperative that systems like this be “biologist friendly.” Otherwise, she said, the breakthroughs needed to solve cancer just won’t happen.
“Everyone realizes that there is a need for computing in cancer research. It’s one thing to understand that, and it’s another thing to convince a clinician to actually use these tools,” she said.
f you’re a developer creating a new piece of software, chances are you’ll write your code in what computer scientists like to call a principled way: by using a programming language and other formal processes to create a system that follows computing rules.
Neil Dalchau wants to do the same thing for biology. He’s part of a team that is trying to do computing in cells instead of on silicon.
“If you can do computing with biological systems, then you can transfer what we’ve learned in traditional computing into medical or biotechnology applications,” said Dalchau, a scientist in the biological computation research group at Microsoft’s Cambridge, U.K., lab.
The ultimate goal of this computational approach: to program biology like we program computers. That’s a breakthrough that would open all sorts of possibilities for everything from treating diseases to feeding the world with more efficient crops.
“All aspects of our daily lives will be affected,” said Andrew Phillips, who heads the Biological Computation Research Group.
Phillips said one approach is to create a kind of molecular computer that you would put inside a cell to monitor for disease. If the sensor detected a disease, it would actuate a response to fight it.
That’s a stark improvement over many current cancer treatments, which end up destroying healthy cells in the process of fighting the cancerous ones.
Early, but promising, steps
Phillips cautions that computer scientists are still in the very early stages of this research and those kinds of long-term goals remain far off.
“It’s an ultimate application,” he said.
One big and obvious challenge is that biological systems – including our bodies — are much more mysterious than the hardware – computers – we created to run software.
“We built the computer. We know how it works. We didn’t build the cell, and many of its complex internal workings remain a mystery to us. So we need to understand how the cell computes in order to program it,” Phillips said. “We need to develop the methods and software for analyzing and programming cells.”

Take cancer, for example. Sara-Jane Dunn, a scientist who also is working in the biological computation group, said you can think of cancer as a biological program gone wrong – a healthy cell that has a bug that caused it to glitch. And by the same token, she noted, you can think of the immune system as the machinery that has the ability to fix some, but not all, bugs.
Scientists have learned so much about what causes cancer and what activates the immune system, but Dunn said it’s still early days, and there is still much more work to be done. If her team gets to a point where they understand those systems as well as we understand how to make Microsoft Word run on a PC, they might be able to equip the immune system to mount a powerful response to cancer on its own.
“If we want to be able to program biology, then we actually need to be able to understand what it is biology computes in the first place,” she said. “That is where I think we can have some major impacts.”
Is the ability to program biology like we program computers a moonshot effort? Phillips believes it is an ambitious, long-term goal – but he sees a path to success.
“Like the moonshot, we know that this is technically possible,” he said. “Now it's a matter of making it a reality.”
illions of people worldwide will be diagnosed with cancer this year. For a select few, experts from leading cancer institutions will gather at what are called molecular tumor boards, to review that patient’s individual history and come up with the best, personalized treatment plan based on their cancer diagnosis and genetic makeup.
Hoifung Poon wants to democratize the molecular tumor board, and he’s working with a team of researchers on a tool to do it.
It’s called Project Hanover. It’s a data-driven approach that uses a branch of artificial intelligence called machine learning to automatically do the legwork that makes it so difficult for cancer experts to evaluate every case individually.

“We understand that cancer is often not caused by a single mutation. Instead, it stems from complex interactions of lots of different mutations, which means that you need to pretty much look at everything you know about the genome,” Poon said.
To do that can require sifting through millions of pieces of fragmented information to find all the common ground applicable to this one person and this one cancer case. For a busy oncologist managing many patients, that simply isn’t possible.
That’s why the Microsoft researchers are working on a system that could augment how doctors approach the task today. The system is designed to automatically sort through all that fragmented information to find the most relevant pieces of data – leaving tumor experts with more time to use their expertise to figure out the best treatment plan for patients.
The ultimate goal is to help doctors do all that research, and then to present an Microsoft Azure cloud computing-based tool that lets doctors model what treatments would work best based on the information they have gathered.
“If we can use this knowledge base to present the research results most relevant for each specific patient, then a regular oncologist can take a look and make the best decision,” said Ravi Pandya, a principal software architect at Microsoft who also is working on Project Hanover.
Finding a needle in a haystack with Literome
Project Hanover began with a tool called Literome, a cloud computing-based system that sorts through millions of research papers to look for the genomic research that might be applicable to an individual disease diagnosis.
That’s a task that would be hard for oncologists to do on their own because of sheer volume, and it’s made more complicated by the fact that researchers aren’t always consistent in how they describe their work. That means several research papers focusing on the same genetic information may not have much overlap in language.
“The problem is that people are so creative in figuring out a different way to say the same thing,” Poon said.
To build Literome, Poon and his colleagues used machine learning to develop natural language processing tools that require only a small amount of available knowledge to create a sophisticated model for finding those different descriptions of similar knowledge.
Now, the tool is being expanded to also look at experiments and other sources of information that might be helpful.
Poon’s team also is working with the Knight Cancer Institute at Oregon Health and Science University to help their researchers find better ways to fight a complex and often deadly form of cancer called acute myeloid leukemia.
Brian Druker, the director of the Knight Cancer Institute, said a person with this form of cancer may actually be fighting three or four types of leukemia. That’s made it extremely difficult to figure out the right medicine to use and whether a patient will develop resistance to the treatment.
“It was clear we needed incredibly sophisticated computational efforts to try to digest all the data we were generating and to try to make sense of it,” said Druker, whose previous research led to vastly improved life expectancies for patients with chronic myeloid leukemia.
Druker thinks of this kind of collaboration as a two-way dialogue: His team of experts can provide the hypotheses that help the computer scientists know what to look for in the data. The computer scientists, in turn, can do the analysis needed to help them prove or disprove their hypotheses.
That can then help them more quickly develop the needed treatments and therapies.
“I’ve always believed that the data is trying to tell us what the answer is, but we need to know how to listen to it,” he said. “That’s where the computation comes in.”
I’ve always believed that the data is trying to tell us what the answer is, but we need to know how to listen to it. That’s where the computation comes in.– Brian Druker, Knight Cancer Institute
Druker believes we are just at the beginning of understanding how data can help inform cancer research. In addition to genomic data, he said, researchers also should start looking at what he calls the other “omics,” including proteomics, or the study or proteins, and metabolomics, or the study of chemical processes involving metabolites.
“We’re going to have get beyond the genome,” he said. “The genome is telling us a lot, but it’s not telling us everything.”
Poon said they are still in the early stages of the research, but already they see how it could change, and save, lives.
“We are at this tantalizing moment where we’ve caught a glimpse of this really promising future, but there is so much work to be done,” he said.
hen radiologists want to get the best, most accurate picture of what is going on inside a patient’s body, they often turn to state-of-the-art equipment that costs millions of dollars and can churn out highly detailed images.
And once they get those images? In many cases, the most high-tech thing they’ll use to read them is a human eye.
“Eyeballing works very well for diagnosing,” said Antonio Criminisi, a machine learning and computer vision expert who heads radiomics research in Microsoft’s Cambridge, U.K., lab. “Expert radiologists can look at an image – say a scan of someone’s brain – and be able to say in two seconds, ‘Yes, there’s a tumor. No, there isn’t a tumor.’”
But when it comes to figuring out if a treatment is working or not, Criminisi said a radiologists’ job gets much more difficult. That’s because the human eye isn’t as good at easily measuring the complex ways in which a modern radiology scan can show whether a tumor may be growing, shrinking or changing shape.
Better technology means more data
A few years ago, Giles Maskell, a radiologist and president of the U.K.’s Royal College of Radiologists, said a typical CT scan might have produced 200 images. Now, that same scan might produce 2,000 images – producing a wealth of data that may not even be perceptible to the human eye.
“The fine detail far exceeds our ability to understand it all and to actually process it into something that is meaningful,” Maskell said.
Put simply, radiologists need technology to help them keep up with the technology.
“We need some help to actually present the data to us in ways that make it easy for us to analyze those huge numbers of images,” Maskell said.
That’s where Criminisi’s team comes in. The team’s data-driven approach is focused on a research project that aims to use computer vision and machine learning to augment the radiologists’ expertise by giving them more detailed and consistent measurements.
The system the researchers are working on could eventually evaluate 3D scans pixel by pixel to tell the radiologist exactly how much the tumor has grown, shrunk or changed shape since the last scan.
It also could provide information about things like tissue density, to give the radiologist a better sense of whether something is more likely a cyst or a tumor. And it could provide more fine-grained analysis of the health of cells surrounding a tumor.
“Doing all of that by eye is pretty much impossible,” Criminisi said.
The goal is not to replace the radiologists’ expertise but rather to allow them to do their jobs better.
“There’s always going to be a need for human interpretation,” Maskell said. “The computers and the computer science will allow us to make better decisions.”
Allison Linn is a senior writer at Microsoft. Follow her on Twitter.
Photos by Jonathan Banks / © Microsoft