
Por: Brandon Rohrer, Científico Senior de Datos en Microsoft.
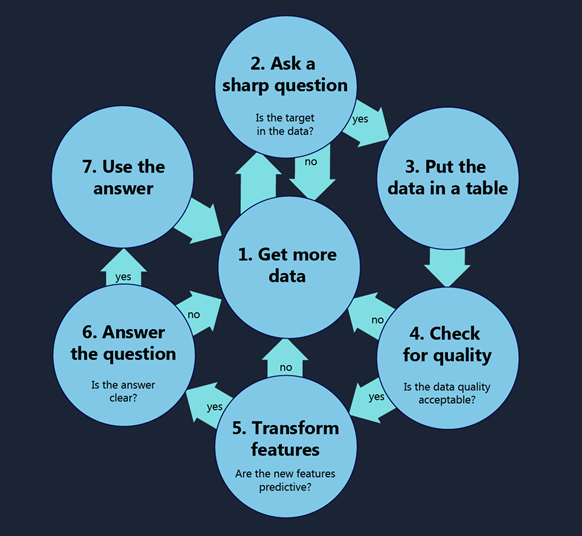
1. Obtengan más datos
El contenido “crudo” de la ciencia de los datos es una colección de números y nombres. Medidas, precios, fechas, tiempos, productos, títulos, acciones –todo se vale. Pueden utilizar imágenes, texto, audio, video y también otros datos complejos, mientras tengan una manera de reducirlos a números y nombres.
La mecánica para obtener datos puede ser algo compleja. Los ingenieros de datos son como ninjas. Pero esta guía está enfocada en la ciencia de los datos, así que dejaré este tema para otra ocasión.
2. Hagan preguntas ingeniosas
La ciencia de los datos es el proceso de utilizar nombres y números para responder una pregunta. Entre más precisa sea su pregunta, mejor oportunidad tendrán de encontrar una respuesta que les satisfaga. Cuando elijan su pregunta, imaginen que se acercan a un oráculo que les puede decir cualquier cosa en el mundo, mientras la respuesta sea un número o un nombre. Es un oráculo travieso, y su respuesta será tan vaga y confusa como quiera. Lo que ustedes quieren es asegurarlo de manera tan perfecta, que el oráculo no tenga otra opción que decirles lo que ustedes quieren saber. Ejemplos de preguntas que no ayudan mucho son “¿Qué pueden decirme los datos sobre mi negocio?”, “¿Qué debería hacer?”, o “¿Cómo puedo incrementar mis ganancias?” Este tipo de preguntas dejan mucho campo para respuestas inservibles. En contraste, respuestas claras a preguntas como “¿Cuántos Artículos del Modelo X venderá en Montreal durante el tercer trimestre?” o “¿Qué auto en mi flotilla fallará primero?” son imposibles de evitar.
Ahora que tienen una pregunta, vean si tienen ejemplos de la respuesta en sus datos. Si su pregunta es “¿Cuál será el precio de mis acciones la siguiente semana?” asegúrense que sus datos incluyen el historial de precios de sus acciones. Si su pregunta es “¿Cuántas horas faltan para que un avión modelo 88 falle?” asegúrense que sus datos incluyen tiempos de falla de algunos motores modelo 88. Estos ejemplos de respuesta se llaman su objetivo. Su objetivo es la cantidad o categoría que quieren predecir o asignar en el futuro. Si no tienen datos objetivo, vayan al paso 1 y Obtengan más datos. No podrán responder su pregunta sin ellos.
3. Pongan los datos en una mesa
La mayoría de los algoritmos de aprendizaje automático asumen que sus datos están en una mesa. Cada fila es un evento o elemento o instancia. Cada columna es una característica o atributo de todas esas filas. Un conjunto de datos que describe al futbol americano debería tener una fila que represente un juego con columnas para equipo_local, equipo_visitante, anotaciones_equipo_local, anotaciones_equipo_visitante, fecha, tiempo_inicio, asistencia y demás. Las columnas pueden ser detalladas de manera arbitraria y puede haber tantas como deseen. El conjunto de datos de futbol podría incluso incluir una columna tan detallada como ésta: yardas_corridas_por_el_equipo_loca_durante_los_dos_últimos_minutos_de_la_primera_mitad
Elijan sus filas
Hay muchas maneras de separar un conjunto de datos en filas, pero solo hay una manera en que les ayudará a responder su pregunta: cada fila necesita tener una y solo una instancia de su objetivo. Consideren datos reunidos de una tienda minorista. Podrían ser condensados a una transacción por fila, un día por fila, una tienda por fila, un cliente por fila, y muchas otras representaciones de fila. Si su pregunta es “¿Regresará un cliente para una segunda visita?”, un cliente por fila será la manera correcta de organizar sus datos. Su objetivo, regresó_el_cliente, aplica solo una vez a cada individuo y será presentado en cada fila. Eso no sucedería si hubiera una tienda por fila o un día por fila. Si terminan con una sola columna objetivo en todas sus filas, se darán cuenta que eligieron la representación de fila adecuada.
Es probable que tengan que mover algunos datos para que todo se ajuste. Por ejemplo, si su pregunta es “¿Cuántos lattes venderé por día?” querrán un día por fila en su mesa, con una columna objetivo de número_de_lattes_vendidos. Pero sus datos podrían ser registrados como una lista de transacciones de venta de lattes con el tiempo y fecha de cada uno. Para que esto se ajuste a un formato de un día por fila, primero es necesario mover los datos, esto es, combinar un conjunto de medidas en una sola. En este caso, significa contar el número de lattes vendidos en cada fecha. Otra información, como el tiempo en el que cada latte fue vendido, está perdida en este proceso, pero está bien. Esos datos no iban a ayudar a responder su pregunta.
4. Revisen su calidad
Inspección
El siguiente paso es dar un cuidadoso paseo a través de los datos. Esto tiene un doble propósito. El primero es encontrar cualquier dato que no sea útil y arreglarlo o removerlo. El otro es familiarizarse a fondo con cada fila y columna. No pueden saltarse este paso y esperar sacar el máximo provecho de sus datos. Si le dan amor a sus datos, ellos los amarán de vuelta.
Vean sólo una columna de datos. ¿Cómo están etiquetados? ¿Los valores se adecúan a la etiqueta? ¿La etiqueta significa algo para ustedes? ¿Existe documentación sobre lo que la columna significa? ¿Sobre qué fueron medidos? ¿Quién los midió? Si tiene la suficiente suerte para saber qué persona los registró, invítenle un café y pregúntenle cómo los midió. Pregúntenle sobre anécdotas curiosas sobre lo que salió mal. Su inversión en esa bebida será pagada con el tiempo.
Ahora tracen la columna como un histograma. ¿La distribución se ajusta a lo que quieren saber sobre la característica? ¿Existe un número inusual de valores atípicos? ¿Los valores atípicos hacen sentido físico? Si buscan longitud de parcelas agrícolas, ¿Algunas están en el Océano Pacífico? Si buscan calificaciones de pruebas, ¿Hay un grupo en uno por ciento? ¿Diez mil por ciento? Utilicen todo lo que saben sobre el origen de los datos y sometan los datos a una prueba de olfato. Si se ven aunque sea un poco fuera de lugar, descubran el por qué.
Corrección
Mientras pasean por las columnas, tal vez encuentren que las etiquetas y la documentación eran confusas o incorrectas. Asegúrense de escribir lo que aprendieron de ellas. En este punto tal vez ya conozcan a los datos mejor que nadie, excepto por la persona que los registró. Compartan su conocimiento.
También es probable que descubran que algunos de los valores están mal. Tal vez el valor esté fuera del rango de posibilidades, como una persona de 72 metros de alto, o que esté elevado de manera improbable, como una dirección “777777777 Avenida Principal”. Cuando esto ocurra, tienen tres opciones. Pueden intentar corregir el valor, si la corrección parece obvia (por ejemplo, convertir 72 metros de altura en 72 pulgadas). Si la corrección no es obvia, pueden borrar el valor y dejarlo como faltante. De manera alterna, si el valor es una pieza crítica de información, pueden remover toda la fila o columna. Esto les evitará entrenar un modelo basado en datos erróneos. Los datos incorrectos son más dañinos que los datos faltantes.
Puede existir la tentación de remover valores o filas que no son deseados. Podrían ser sorprendentes o tal vez no apoyen su teoría favorita. No lo hagan. No es ético y, peor aún, les brindará una respuesta errónea.
Reemplazar valores faltantes
Casi en cada conjunto de datos hay valores faltantes. En ocasiones se descubre que son erróneos y son eliminados. En ocasiones ustedes comienzan a medir una nueva variable a la mitad del experimento. En ocasiones los datos vienen de diferentes fuentes que midieron cosas distintas. Cualquiera que sea el caso, la mayoría de los algoritmos de aprendizaje de máquina requieren que los datos no tengan valores perdidos o, que llenen cualquier valor faltante de manera ingenua. Ustedes pueden hacerlo mejor, porque ustedes entienden a los datos.
Hay muchos métodos para reemplazar valores faltantes. Si quieren ver una muestra vean este experimento en Azure Machine Learning. El punto es que la mejor cosa por hacer dependerá en lo que cada columna significa y lo que significa cuando uno de esos valores falte. Será una pequeña diferencia para cada conjunto de datos.
Una vez que hayan reemplazado todos los valores faltantes, sus datos estarán “conectados”. Cada punto de dato tiene un valor para cada característica. Está limpio y listo para trabajar en él. De manera ocasional, tal vez descubran que después de la limpieza, tienen pocos datos o ninguno. Esto es bueno. Se ahorraron la molestia de construir un modelo con datos malos, obtener un resultado equivocado, incluso de recibir burlas por parte de sus clientes y molestar a su jefe. Regresen al paso 1 y Obtengan más datos.
5. Transformen las características
Antes de entrar al aprendizaje automático, falta un paso: la ingeniería de características. Esto tan solo significa que tomen las características que tienen y las combinen de manera creativa para que hagan una mejor predicción de su objetivo. Tomen este ejemplo en el que los tiempos de llegada y salida de un tren son sustraídos para obtener duración del tránsito. Esto probó más utilidad para predecir el objetivo, velocidad pico.
Hablando de manera estricta, la ingeniería de características no agrega información a los datos. Sólo se trata de combinar lo que hay de una nueva manera. Sin embargo, hay maneras infinitas de combinar incluso dos columnas de datos. Muchas de estas no serán significativas o ayudan a predecir el objetivo. Elegir una buena por lo general requiere conocimiento del mundo. Es una manera en la que pueden plegar su conocimiento sobre el problema en los datos y acomodar las cosas a su favor.
El proceso de ingeniería de características es la más oscura de las artes de la ciencia de los datos. No hay una manera recta de elegir de manera automática las mejores características derivadas. Es un proceso de prueba y error, intuición y experiencia. Todo el aprendizaje profundo es un intento de automatizar el proceso. Para llegar a tener éxito, el aprendizaje profundo es complicado y aún tiene fallas espectaculares. Se podría decir que la receta secreta de la inteligencia humana es la capacidad de crear características de manera automática a partir de un gran número de barras, códigos y corpúsculos pacinianos.
Incluso si aún no han conseguido el rango de cinta negra en ingeniería de características, hay un truco que pueden utilizar. Codifiquen por color su objetivo y trácenlo contra cada par de variables que tengan. Esto ayudará a exponer relaciones escurridizas entre variables. Esto podría generar muchos trazos, pero tómense el tiempo de verlas a todas. Cada vez que vean un patrón en estos trazos de dos características por objetivo, será una oportunidad de hacer ingeniería de características. Esto les dice que la combinación de esas dos variables podría ser de más ayuda que las dos variables solas.
Hay mucho más por decir sobre la ingeniería de características. Espero regresar pronto a esto y agregar aquí ligas a la discusión.
En ocasiones descubrirán que ninguna de sus variables o combinaciones de variables ayuda a predecir su objetivo. Esto tal vez signifique que necesitan medir otra cosa. Vayan al paso 1 y Obtengan más datos.
6. Respondan la pregunta
Por último, han llegado a la parte favorita de los científicos de datos. ¡El aprendizaje automático! Hay muchos recursos disponibles sobre esto y no trataré de sumarizarlos aquí. De manera breve, ustedes tienen que decidir a qué familia de algoritmos pertenece su pregunta, elegir uno o más algoritmos dentro de esa familia para utilizarlos y luego giren la manivela, utilizando las técnicas tradicionales de aprendizaje automático de dividir los datos en entrenamiento, afinación y prueba de conjuntos de datos y optimizando los parámetros en cualquier modelo(s) que hayan elegido.
Si su modelo no responde su pregunta de manera adecuada o quisieran evitar hacer aprendizaje automático, existen algunas maneras no tradicionales de responder su pregunta.
La primera de ellas es tan solo ver imágenes de sus datos. La mitad del tiempo, visualizar sus datos les da la respuesta que buscan. Si su pregunta es “¿Cuál será la temperatura alta en Boston el 4 de julio del siguiente año?”, ver un histograma de altas temperaturas en Boston para el 4 de julio en los últimos 100 años ofrece una respuesta visual que bastará para la mayoría de los propósitos. Dos mapas de calor de dos dimensiones son en particular efectivos para la combinación de dos características con un objetivo de manera que sea fácil para nuestro sistema visual interpretar y recordar.
La segunda de estas es más demandante a nivel técnico. Si sus resultados no son satisfactorios porque su conjunto de datos es muy pequeño, se pueden desviar hacia el terreno de la optimización. Este es un tema profundo al que planeo regresar en un futuro. Por ahora les dejaré un avance. Los algoritmos de aprendizaje automático presentan debilidades previas, esto es, que hacen suposiciones débiles sobre la estructura de los datos. El lado bueno de este enfoque es que no se requiere mucho conocimiento de su parte sobre los datos antes de utilizar los algoritmos. Ellos pueden aprender una amplia clase de modelos. El lado malo es que se necesitan muchos datos para recibir una respuesta confiable. Una alternativa para esto es hacer más suposiciones sobre sus datos –para incorporar lo que saben sobre el mundo en sus suposiciones.
Por ejemplo, si quieren predecir la trayectoria balística de un objeto, ustedes pueden recolectar datos de diferentes objetos en caída libre y entrenar sobre ellos al algoritmo de aprendizaje automático. De manera alterna, pueden utilizar lo que saben sobre física de Newton para crear un modelo más rico. Luego, un solo punto de dato que incluya posición y velocidad es suficiente para predecir la posición y velocidad del objeto en cada punto en el futuro. El riesgo de este enfoque es que sus suposiciones no son correctas de manera exacta, pero la fortaleza es que pueden tener por mucho, menos datos.
Si ninguno de estos métodos les funciona, es probable que se trate de una señal de que necesitan recolectar más datos o repensar lo que miden. Vayan al paso 1 y Obtengan más datos.
7. Utilicen la respuesta
No importa qué tan bien utilicen sus datos para responder su pregunta, su trabajo no está finalizado hasta que una persona los utilice. Colóquenlos de manera que alguien los pueda utilizar ya sea para tomar una decisión, completar una tarea o aprender algo que no sabían. Hay muchas maneras de hacer esto. Publiquen trazos de resultados en una página web. Escriban un PDF que muestre las características que encontraron más útiles. Compartan su código en GitHub. Hagan un video en el que compartan sus conclusiones con una audiencia de negocios. Generen una llamativa visualización y publíquenla en Twitter. Den un giro a un servicio web que aplique su modelo en nuevos puntos de datos. Cualquier cosa que decidan hacer, pongan su trabajo en las manos de otra persona. Si un árbol cae en el bosque y nadie está cerca para escucharlo, es probable que haga ruido, pero si ustedes construyen un modelo brillante y nadie lo ve, seguramente éste no les conseguirá un aumento.
Luego empiecen de nuevo. Vayan al punto 1 y Obtengan más datos.
Brandon
Síganme en Twitter @_brohrer_




