


Sometimes the best way to solve a complex problem is to take a page from a children’s book. That’s the lesson Microsoft researchers learned by figuring out how to pack more punch into a much smaller package.
Last year, after spending his workday thinking through potential solutions to machine learning riddles, Microsoft’s Ronen Eldan was reading bedtime stories to his daughter when he thought to himself, “how did she learn this word? How does she know how to connect these words?”
That led the Microsoft Research machine learning expert to wonder how much an AI model could learn using only words a 4-year-old could understand – and ultimately to an innovative training approach that’s produced a new class of more capable small language models that promises to make AI more accessible to more people.
Large language models (LLMs) have created exciting new opportunities to be more productive and creative using AI. But their size means they can require significant computing resources to operate.
While those models will still be the gold standard for solving many types of complex tasks, Microsoft has been developing a series of small language models (SLMs) that offer many of the same capabilities found in LLMs but are smaller in size and are trained on smaller amounts of data.
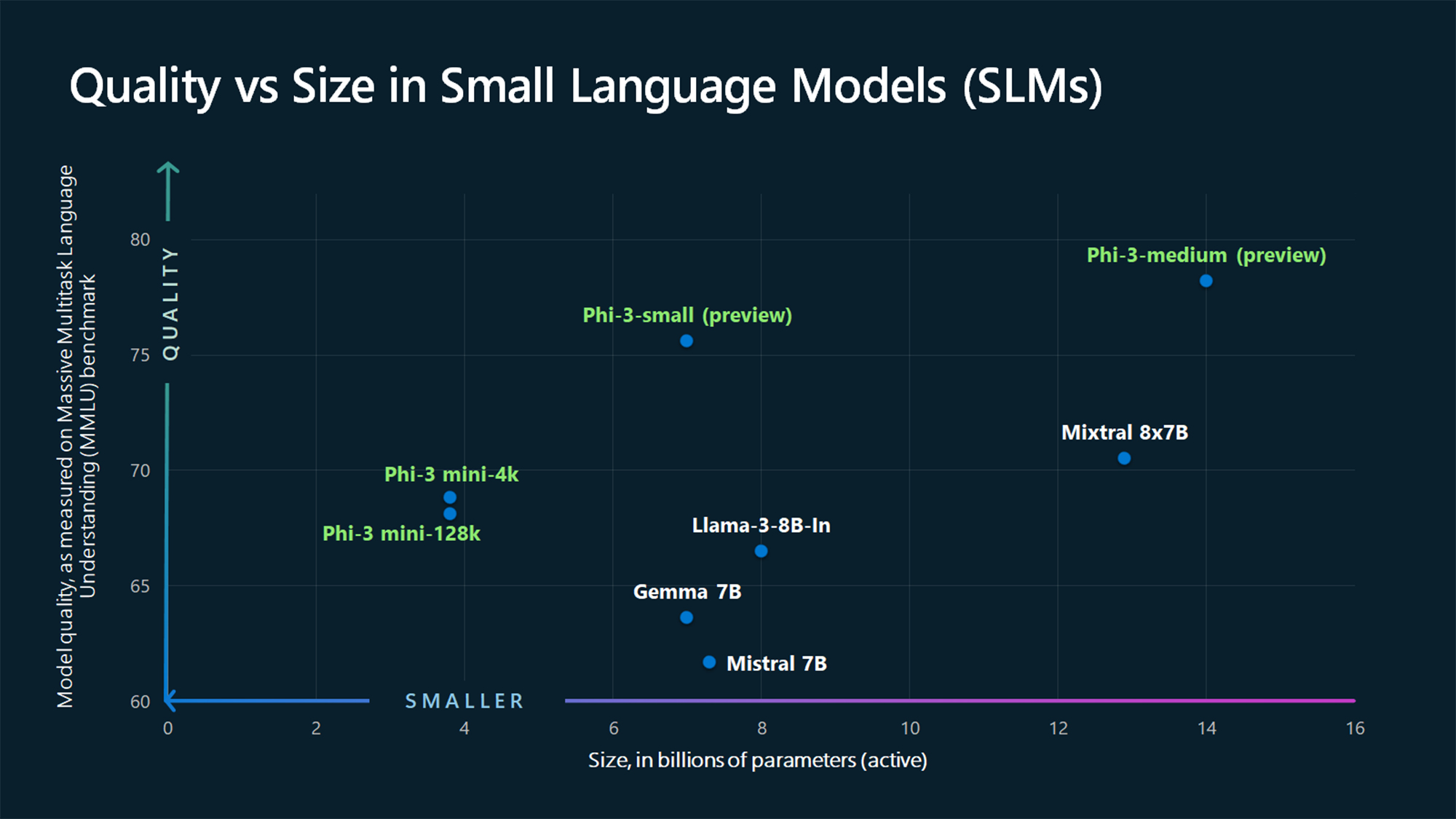
The company announced today the Phi-3 family of open models, the most capable and cost-effective small language models available. Phi-3 models outperform models of the same size and next size up across a variety of benchmarks that evaluate language, coding and math capabilities, thanks to training innovations developed by Microsoft researchers.
Microsoft is now making the first in that family of more powerful small language models publicly available: Phi-3-mini, measuring 3.8 billion parameters, which performs better than models twice its size, the company said.
Starting today, it will be available in the Microsoft Azure AI Model Catalog and on Hugging Face, a platform for machine learning models, as well as Ollama, a lightweight framework for running models on a local machine. It will also be available as an NVIDIA NIM microservice with a standard API interface that can be deployed anywhere.
Microsoft also announced additional models to the Phi-3 family are coming soon to offer more choice across quality and cost. Phi-3-small (7 billion parameters) and Phi-3-medium (14 billion parameters) will be available in the Azure AI Model Catalog and other model gardens shortly.
Small language models are designed to perform well for simpler tasks, are more accessible and easier to use for organizations with limited resources and they can be more easily fine-tuned to meet specific needs.
“What we’re going to start to see is not a shift from large to small, but a shift from a singular category of models to a portfolio of models where customers get the ability to make a decision on what is the best model for their scenario,” said Sonali Yadav, principal product manager for Generative AI at Microsoft.
“Some customers may only need small models, some will need big models and many are going to want to combine both in a variety of ways,” said Luis Vargas, vice president of AI at Microsoft.
Choosing the right language model depends on an organization’s specific needs, the complexity of the task and available resources. Small language models are well suited for organizations looking to build applications that can run locally on a device (as opposed to the cloud) and where a task doesn’t require extensive reasoning or a quick response is needed.
Large language models are more suited for applications that need orchestration of complex tasks involving advanced reasoning, data analysis and understanding of context.
Small language models also offer potential solutions for regulated industries and sectors that encounter situations where they need high quality results but want to keep data on their own premises, said Yadav.
Vargas and Yadav are particularly excited about the opportunities to place more capable SLMs on smartphones and other mobile devices that operate “at the edge,” not connected to the cloud. (Think of car computers, PCs without Wi-Fi, traffic systems, smart sensors on a factory floor, remote cameras or devices that monitor environmental compliance.) By keeping data within the device, users can “minimize latency and maximize privacy,” said Vargas.
Latency refers to the delay that can occur when LLMs communicate with the cloud to retrieve information used to generate answers to users prompts. In some instances, high-quality answers are worth waiting for while in other scenarios speed is more important to user satisfaction.
Because SLMs can work offline, more people will be able to put AI to work in ways that haven’t previously been possible, Vargas said.
For instance, SLMs could also be put to use in rural areas that lack cell service. Consider a farmer inspecting crops who finds signs of disease on a leaf or branch. Using a SLM with visual capability, the farmer could take a picture of the crop at issue and get immediate recommendations on how to treat pests or disease.
“If you are in a part of the world that doesn’t have a good network,” said Vargas, “you are still going to be able to have AI experiences on your device.”
The role of high-quality data
Just as the name implies, compared to LLMs, SLMs are tiny, at least by AI standards. Phi-3-mini has “only” 3.8 billion parameters – a unit of measure that refers to the algorithmic knobs on a model that help determine its output. By contrast, the biggest large language models are many orders of magnitude larger.
The huge advances in generative AI ushered in by large language models were largely thought to be enabled by their sheer size. But the Microsoft team was able to develop small language models that can deliver outsized results in a tiny package. This breakthrough was enabled by a highly selective approach to training data – which is where children’s books come into play.
To date, the standard way to train large language models has been to use massive amounts of data from the internet. This was thought to be the only way to meet this type of model’s huge appetite for content, which it needs to “learn” to understand the nuances of language and generate intelligent answers to user prompts. But Microsoft researchers had a different idea.
“Instead of training on just raw web data, why don’t you look for data which is of extremely high quality?” asked Sebastien Bubeck, Microsoft vice president of generative AI research who has led the company’s efforts to develop more capable small language models. But where to focus?
Inspired by Eldan’s nightly reading ritual with his daughter, Microsoft researchers decided to create a discrete dataset starting with 3,000 words – including a roughly equal number of nouns, verbs and adjectives. Then they asked a large language model to create a children’s story using one noun, one verb and one adjective from the list – a prompt they repeated millions of times over several days, generating millions of tiny children’s stories.
They dubbed the resulting dataset “TinyStories” and used it to train very small language models of around 10 million parameters. To their surprise, when prompted to create its own stories, the small language model trained on TinyStories generated fluent narratives with perfect grammar.
Next, they took their experiment up a grade, so to speak. This time a bigger group of researchers used carefully selected publicly-available data that was filtered based on educational value and content quality to train Phi-1. After collecting publicly available information into an initial dataset, they used a prompting and seeding formula inspired by the one used for TinyStories, but took it one step further and made it more sophisticated, so that it would capture a wider scope of data. To ensure high quality, they repeatedly filtered the resulting content before feeding it back into a LLM for further synthesizing. In this way, over several weeks, they built up a corpus of data large enough to train a more capable SLM.
“A lot of care goes into producing these synthetic data,” Bubeck said, referring to data generated by AI, “looking over it, making sure it makes sense, filtering it out. We don’t take everything that we produce.” They dubbed this dataset “CodeTextbook.”
The researchers further enhanced the dataset by approaching data selection like a teacher breaking down difficult concepts for a student. “Because it’s reading from textbook-like material, from quality documents that explain things very, very well,” said Bubeck, “you make the task of the language model to read and understand this material much easier.”
Distinguishing between high- and low-quality information isn’t difficult for a human, but sorting through more than a terabyte of data that Microsoft researchers determined they would need to train their SLM would be impossible without help from a LLM.
“The power of the current generation of large language models is really an enabler that we didn’t have before in terms of synthetic data generation,” said Ece Kamar, a Microsoft vice president who leads the Microsoft Research AI Frontiers Lab, where the new training approach was developed.
Starting with carefully selected data helps reduce the likelihood of models returning unwanted or inappropriate responses, but it’s not sufficient to guard against all potential safety challenges. As with all generative AI model releases, Microsoft’s product and responsible AI teams used a multi-layered approach to manage and mitigate risks in developing Phi-3 models.
For instance, after initial training they provided additional examples and feedback on how the models should ideally respond, which builds in an additional safety layer and helps the model generate high-quality results. Each model also undergoes assessment, testing and manual red-teaming, in which experts identify and address potential vulnerabilities.
Finally, developers using the Phi-3 model family can also take advantage of a suite of tools available in Azure AI to help them build safer and more trustworthy applications.
Choosing the right-size language model for the right task
But even small language models trained on high quality data have limitations. They are not designed for in-depth knowledge retrieval, where large language models excel due to their greater capacity and training using much larger data sets.
LLMs are better than SLMs at complex reasoning over large amounts of information due to their size and processing power. That’s a function that could be relevant for drug discovery, for example, by helping to pore through vast stores of scientific papers, analyze complex patterns and understand interactions between genes, proteins or chemicals.
“Anything that involves things like planning where you have a task, and the task is complicated enough that you need to figure out how to partition that task into a set of sub tasks, and sometimes sub-sub tasks, and then execute through all of those to come with a final answer … are really going to be in the domain of large models for a while,” said Vargas.
Based on ongoing conversations with customers, Vargas and Yadav expect to see some companies “offloading” some tasks to small models if the task is not too complex.

For instance, a business could use Phi-3 to summarize the main points of a long document or extract relevant insights and industry trends from market research reports. Another organization might use Phi-3 to generate copy, helping create content for marketing or sales teams such as product descriptions or social media posts. Or, a company might use Phi-3 to power a support chatbot to answer customers’ basic questions about their plan, or service upgrades.
Internally, Microsoft is already using suites of models, where large language models play the role of router, to direct certain queries that require less computing power to small language models, while tackling other more complex requests itself.
“The claim here is not that SLMs are going to substitute or replace large language models,” said Kamar. Instead, SLMs “are uniquely positioned for computation on the edge, computation on the device, computations where you don’t need to go to the cloud to get things done. That’s why it is important for us to understand the strengths and weaknesses of this model portfolio.”
And size carries important advantages. There’s still a gap between small language models and the level of intelligence that you can get from the big models on the cloud, said Bubeck. “And maybe there will always be a gap because you know – the big models are going to keep making progress.”
Related links:
- Read more: Introducing Phi-3, redefining what’s possible with SLMs
- Learn more: Azure AI
- Read more: Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Top image: Sebastien Bubeck, Microsoft vice president of Generative AI research who has led the company’s efforts to develop more capable small language models. (Photo by Dan DeLong for Microsoft)