
コンピューターサイエンティストは、ゲーム AI に対して常に高い関心を持っています。それは、囲碁や将棋での強さを向上するためではなく、人工知能(AI)のアルゴリズムと複雑な問題の解決能力を上げ続けていくためです。実際、ゲーム AI は AI そのものと同じくらいの長い歴史があります。そして、AI に関する研究の多くは、ゲームをプレイできるエージェントを構築するための研究に由来しています。つまり、ゲーム AI も、AI そのものの研究の進展にともなって進化してきたと言えます。
バックギャモンやチェッカー、チェス、ポーカー、囲碁などのようなゲームが、AI の研究の対象とされたのは次のような特徴があるからです。
1) シンプルで明確なルールがあり、勝負判定と行動の基準が明確であること。
2) こういったゲームに精通していることは、人間の知能が一定以上高いことを示している、との一般的な認識があること。
1956 年、強化学習アルゴリズムがチェッカーに採用される
実は、アラン・チューリング(Alan Turing)が AI の概念を提唱する前に、コンピューターサイエンティストは、既に自ら書いた「知能」プログラムをゲームでテストしていました。
1928 年、ジョン・フォン・ノイマン(John Vonn Neuman)は Minimax(ミニマックス定理)のアルゴリズムを発表しました。そして 1949 年、クロード・シャノン(Claude Shannon)によってこのアルゴリズムが再構築され、チェッカーの問題解決に使われるようになりました。1956 年のダートマス会議では、AIを学術研究分野として確立しました。同じ年に、アーサー・サミュエル(Arthur Samuel)は、自ら学ぶことによってチェッカー(Checkers)をプレイできるアルゴリズムを開発しています。そのアルゴリズムは今、強化学習(Reinforcement Learning)と呼ばれています。
1992 年のバックギャモンにおけるブレイクスルー
バックギャモン(Backgammon)の AI におけるブレイクスルーは、AI 研究史の画期的な出来事とされています。1970 年代、ドイツのチェス棋士ハンス ベルリナー(Hans Berliner)によってバックギャモンの AI プログラム「BKG 9.8」が開発されました。
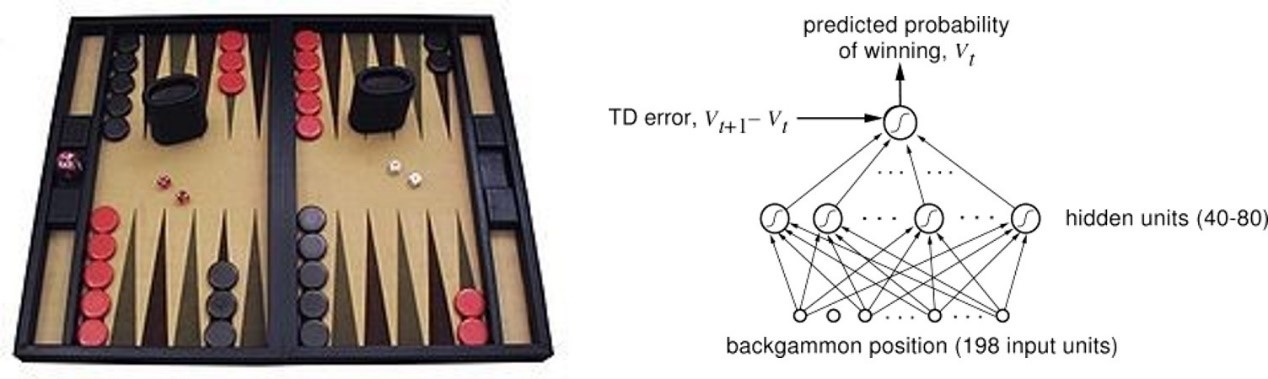
1992 年に入ると、ジェラルド テサウロ(Gerald Tesauro)によって TD-Gammon というプログラムが開発されます。このプログラムは、ニューラルネットワークをモデルとして、TD (λ) 法によって訓練されました。自己対戦を大量に繰り返すことで、人間のトップレベルに達した TD-Gammon は、人間プレイヤーを必要としない訓練法を使用したからこそ、人間プレイヤーと異なるゲームプレイを見せてくれました。TD-Gammon の意義は、強化学習を使用して訓練しただけでなく、特徴量エンジニアリング(生のデータを統計学や機械学習で成果を出せるデータに変換する方法)を必要とせず、駒の位置をニューラルネットワークに入力するだけで、世界チャンピオンレベルの人間プレイヤーに匹敵するエージェントを訓練できると証明したことにあります。
1990 年代、チェッカー・チェス AI が人間に追いつく
コンピューターの計算能力が大幅に向上し、AI のアルゴリズムが次第に発展する中、チェッカー向けのアルゴリズムをサミュエルが開発してから 38 年が経った 1994 年、アルバータ大学のジョナサン シェーファー(Jonathan Schaeffer)教授はチームを導いて Chinook を開発しました。このプログラムのコアとして、探索木アルゴリズムも使用されています。探索木の計算の複雑度を低減させ、予測関数の精度を上げるために、世界中のチェッカーマスターのゲーム開始時の行動と終盤の盤面、勝負情況などを含めたデータベースを作成した上、手動調整に基づいたアルファ・ベータ法も使っています。
1994 年、Chinook は、チェッカーの世界タイトル戦で世界チャンピオンのマリオン ティンズリー(Marion Tinsley)と対戦しました。Chinook と 6 局連続引き分けた後、ティンズリーは体調を崩して試合を放棄し、Chinook は人間プレイヤーとの戦いでチェッカーの世界チャンピオンのタイトルを手に入れた初の AI プログラムとなりました。シェーファー教授は、2007 年に発表した論文で、この試合によって、AI がチェッカーの問題を解けると証明されたと述べています。

一方、チェス AI の分野でも、許峰雄(シュウ ファンション)が主導するディープ ソート(Deep Thought)研究チームがブレイクスルーを見せました。ディープ ソートには検索を加速させるための特別なハードウェアデザインが使用された上、「Singular Extensions」というアルゴリズムも導入されました。そのコアとなるアイディアは、候補となる手の中で、他の候補よりも一定以上優れていると評価された手がある場合、その手に関して更に深く探索をするというものです。
その後、ディープ ソートチームは IBM に入社し、これまでの研究を引き継ぐ形で、大型コンピューター「Big Blue(後にディープ ブルー/ Deep Blue に改称)の開発を行います。1997 年、ディープ ブルーは、チェス世界チャンピオンのガルリ カスパロフ(Garry Kasparov)との対戦で 3.5:2.5 のスコアで勝利します。ディープ・ブルーは対局時に、当時としては非常に高い計算能力を有する、専用に設計された大型コンピューターによって 1 秒間に 2 憶手を読むことができ、さらにその次の 12 手(Singular Extensions を使用した場合は 40 手)を探ることを実現しました。ついに、ディープ ブルーはトーナメントの条件下で、人間のチェス世界チャンピオンに勝利した初のコンピュータープログラムとなったのです。
囲碁 AI の進化、歴史的快挙を達成
これまでに見てきたゲームと比較して、1 手に 19×19 の選択肢がある囲碁は、はるかに複雑であり、チェスなどよりも難しいゲームとされています。
1968 年、初の囲碁プログラムがアルベルト ゾブリスト(Albert Zobrist)によって開発されましたが、勝利できたのは初級レベルのプレイヤーのみでした。1993 年、ベルン ブルーグマン(Bernd Brügmann)は、評価関数の代わりにモンテカルロ法を用いる「Monte Carlo Go」というプログラムを開発しました。「Monte Carlo Go」は、注意深く設計された評価関数値の代わりにモンテカルロ法を使用したため、 Monte Carlo Go は任務によって結果へ導く評価関数を設計することなく、結果予測値の代わりにロールアウト(rollout)—— 終盤まで自己対戦—— の平均値を使っています。このアルゴリズムは、後に AlphaGo を成功に導いた中心的なアルゴリズムの一つともされています。
2006 年、フランス国立情報学自動制御研究所(INRIA)の研究員シルヴァン ゲリー (Sylvain Gelly) は、Monte Carlo Go のもとに UCT アルゴリズムを導入し、 MoGo というプログラムを開発しました。2008 年、MoGo は 7 子のハンデをもらい、キム ミョンワン(Kim Myung Wan)プロ八段棋士に勝利しました。MoGo の勝利によって、MCTS(UCT)アルゴリズムの囲碁問題解決における重要性が十分に証明されました。
2015 年、DeepMind チームは、上記プログラムをもとに深層強化学習に基づいたプログラム「AlphaGo」を開発しました。囲碁の欧州チャンピオンに勝利した「AlphaGo」は、ハンデなしで 19 路盤でプロ棋士に勝った初の囲碁プログラムとなったのです。
さらに複雑度の高い不完全情報ゲーム AI 、歴史の舞台へ登場
ポーカーやブリッジ、麻雀などは、これまで見たチェスや囲碁などの棋類ゲームと種類の違うゲームとされています。こういったゲームをプレイする時、プレイヤー同士はお互いの情報をすべて把握することができないため、不完全情報ゲーム(imperfect information game)と呼ばれています。
テキサス・ホールデム(ポーカーのルールの一つ)のような不完全情報ゲームでは、情報の不完全性を利用して、ブラフ(Bluff)によって相手を惑わすことができます。トップレベルの人間プレイヤーは、こうしたスキルを使いこなしています。テキサス・ホールデム AI はアルバータ大学の研究者が性能向上に向けて継続的に開発し続けています。 1984 年、プロのポーカープレイヤー マイク カロ(Mike Caro)が Orac を開発してから、1997 年、前出のシェーファーは、テキサス・ホールデム・プレイヤーのブラフ行為をシミュレートする Loki を開発しました。Loki は 2001 年に PsOpti と改称され、ゲーム理論に基づいた手法が導入されました。そして 2015 年、Cepheus が発表されます。これに加え、CFR+ アルゴリズムを使用した Cepheus によって、ヘッズアップ・リミット・テキサスホールデム(1 対 1、ベット上限額有り)が解かれ、コンピューターがベット上限額有りのルールにおいて人間に勝てると証明されました。2017 年、カーネギーメロン大学とアルバータ大学は相次いで Libratus と DeepStack を発表し、ヘッズアップ・ノーリミット・テキサスホールデム(1 対 1、ベット上限額無し)において世界チャンピオンに勝利しました。2019 年、カーネギーメロン大学は、Facebook AI と共に Libratus の進化版として Pluribus を開発し、6 人でのノーリミット・テキサスホールデムでプロのポーカープレイヤーを打ち負かしています。
一方、ゲーム戦略は、この情報の不完全性によってさらに複雑になっており、探索木と CFR アルゴリズムに基づいた計算もより一層複雑さを増しています。その中で、トランプゲームの一種であるブリッジは複雑なルール(アスキングビッドと手札のプレイを含む)があるため、AI の研究対象になっています。1980 年代より Bridge Baron のプログラム開発を進めていた、米海軍の研究施設に所属していたトム スロープ(Tom Throop)は、十数年にわたる開発によって、1997 年に世界初のコンピューターブリッジ試合で優勝を収めます。翌年、その試合では、オレゴン大学のマシュー ギンズバーグ(Matthew Ginsberg)が開発した GIB プログラムが優勝しました。GIB プログラムは同年、世界ブリッジ選手権の参加に招かれ、35 名の参加者の中で第 12 位の成績を収めました。十数年後、モンテカルロ法に基づいた Jack と Wbridge5 もそれぞれ、世界ブリッジ選手権に参加し、優勝しています。麻雀の分野では、2015 年に東京大学の水上直紀が「爆打」という AI プログラムを開発、2018 年に株式会社ドワンゴもディープ・ラーニングモデルに基づいた麻雀AI 「NAGA」を開発していますが、まだトップレベルの人間プレイヤーとの差がある状況です。
将棋や囲碁のような「完全情報」ゲームや、テキサス・ホールデムのような「不完全情報」のポーカーゲームよりも、ブリッジや麻雀における AI を開発する方がよりチャレンジングだと言えるかもしれません。「不完全情報」の特徴だけでなく、「不完全情報」ゲームの中でも、観測することのできない状態空間がとりわけ広く、現実世界の中で人間が意思決定をする過程により近くなっているからです。そのため、このようなゲーム AI におけるブレイクスルーは、次のゲーム AI 研究の画期的な出来事になるかもしれません。

参考資料:
[1] http://www.bridgeguys.com/CGlossary/Computer/CBProgrammers.pdf
[2] http://gameaibook.org/book.pdf
[3] http://www.andreykurenkov.com/writing/ai/a-brief-history-of-game-ai/
—
本ページのすべての内容は、作成日時点でのものであり、予告なく変更される場合があります。正式な社内承認や各社との契約締結が必要な場合は、それまでは確定されるものではありません。また、様々な事由・背景により、一部または全部が変更、キャンセル、実現困難となる場合があります。予めご了承下さい。




