«Сколько стоит Мона Лиза?»
Ответит умный поиск, который наряду с другими продуктами Microsoft был улучшен благодаря исследованиям в области ИИ
До недавнего времени мультинациональным компаниям для помощи клиентам при бронировании международных перелетов на каждом языке приходилось писать чат-бот с нуля: на французском, хинди, японском и т.д.
Благодаря достижениям в развитии искусственного интеллекта были созданы алгоритмы, способные досконально проанализировать разные языки, детально разобрать способы словесного выражения разных понятий и структуры предложений. Это сделало возможным переводить вопросы и ответы с разных языков с высокой точностью, создав всего лишь один бот и используя Microsoft Translator.
В последние годы специалисты Microsoft по глубокому обучению стали лидерами в достижении алгоритмами паритета с человеком в таких областях, как распознавание разговорной речи, понимание смысла прочитанного, перевод новых текстов и другие сложные лингвистические задачи. Сейчас результаты этих прорывных исследований нашли свое практическое применение в различных продуктах от Azure до Bing.
Инженеры поисковых систем уже готовы перенимать опыт у исследователей ИИ из Microsoft, которые разработали новую модель глубоких нейронных сетей, способную обучаться одновременно на множественных задачах понимания естественного языка. Они уже применили новые знания для совершенствования результатов поисковых сервисов Bing и ответов на вопросы на корпоративных сайтах SharePoint. Новая ИИ-модель, показавшая отличные результаты распознавания спикера в независимом тесте Speaker recognition challenge, уже включается в Azure Speaker Recognition Cognitive Service.
«На самом деле, только благодаря недавнему внедрению новых моделей глубокого обучения удалось качественно улучшить понимание языка, – сказал Эрик Бойд, корпоративный вице-президент Microsoft по Azure AI. – Сейчас наши продукты в состоянии решать такие задачи, которые были просто невозможны до этих исследовательских прорывов».
Он приводит примеры случаев, когда разработки продуктов на основе Azure AI изначально были нацелены на сугубо исследовательские задачи, но потом превратились в полезные продукты для потребителей. Например, возможности автоматизированного машинного обучения на Azure, которые существенным образом упрощают процесс построения моделей или Azure Personalizer Cognitive Service, который легко доставляет релевантный контент до конечных пользователей. Последнюю модель обучения с подкреплением, изначально разработанную для исследований, опробовали сначала внутри компании, а затем встроили в продукт на облачной технологии Azure.
«Эта область развивается настолько стремительно, что для работы вам необходимы самые последние научные теории и разработки. Но кроме этого, нужна огромная армия суперталантливых людей из Microsoft Research, которые будут расталкивать границы ваших идей в самых разных направлениях, – говорит Бойд. – Поэтому наша работа заключается в обнаружении наиболее перспективных областей, которые мы будем включать в продукты, а с другой стороны, придании им интересного для нас вектора».
Например, в области перевода в 2018 г. исследователи Microsoft первыми продемонстрировали паритет ИИ и человека в переводе новостных статей с китайского на английский на универсальном тестовом датасете. Как только команда ученых достигла этой исторической вехи в исследовании, началась адаптация этой модели для использования в Microsoft Translator, который обеспечивается мощностью вычислений Azure Cognitive Service. Новый продукт должен осуществлять моментальный перевод огромного разнообразия текстов от исторических исследовательских архивов и веб-страниц для путешественников до справочной производственной документации.
В прошлом июне полученные усовершенствования были внедрены в первые 9 языковых пар для перевода на английский и с английского, а в ноябре были освоены еще 8 новых языков. Так, например, перевод с английского на французский улучшился на 9%, с английского на хинди на 9%, с бенгали на английский на 11%, урду на английский на 15% и с английского на корейский на 22%. Даже уже продвинутые сильные модели, такие как для португальского или шведского языков, получили значительные доработки.
«С таким очевидным прогрессом в качестве перевода становится абсолютно приемлемым, например, взять HR-документ, написанный на одном языке, использовать машинный перевод – теперь уже не требующий последующего редактирования – и просто переслать готовый результат в нужную страну, – говорит выдающийся инженер Microsoft и основатель Microsoft Translator Аруль Менезес. – А для инженера на заводе в случае поломки оборудования появляется возможность легко связаться с экспертом, который находится в другом регионе и говорит на другом языке».
«Мы на самом деле уже подбираемся к точке, когда автоматический перевод будет очень высококачественным, и все больше клиентов начинают использовать его для новых приложений, о чем раньше они даже не мечтали», – сказал Менезес.
Эволюция от исследования до продукта
Одно дело использовать всевозможные «технические навороты» и мощную вычислительную инфраструктуру Azure для моделей машинного перевода на основе ИИ, которые будут соответствовать уровню качества перевода человеком в узких рамках исследовательского проекта и в определенном диапазоне данных. Совсем другое – создать модель, работающую в коммерческом продукте.
Для решения задачи достижения машиной паритета с человеком три исследовательские команды использовали глубокие нейросети и самые передовые методы обучения, копирующие человеческий подход и способы перевода. В частности, они включали перевод в обе стороны между английским и китайским, затем сравнение результатов и повторение процесса снова и снова, пока не будет достигнуто высокое качество перевода.
«Вначале мы не учитывали, можно ли эту технологию считать готовой для внедрения в продукты. Мы просто задались вопросом, а что если мы возьмем все, что у нас есть, и приложим к нашей проблеме, насколько это поможет нам? – поясняет Менезес. – И вот мы пришли к этой исследовательской системе, которая оказалась очень громоздкой, очень медленной и очень дорогой, только для того чтобы хотя бы придвинуться к достижению паритета с человеком».
«С того момента нашей целью стало вычисление, как можно передать этот уровень качества – или максимально приближенный к нему – в наши производственные API, – продолжает Менезес. – Пользователь переводчика Microsoft набирает на клавиатуре предложение, ожидая перевод за миллисекунды. Таким образом, перед командой стала новая задача, как большую сложную модель для исследования сделать быстрой и наименее затратной. Специалисты работали над тем, чтобы сократить исследовательскую систему алгоритмически, но одновременно вынуждены были экспоненциально расширить охват и тренировать не только на новостных статьях, а на чем угодно, от кулинарных рецептов до энциклопедических статей.
Команда разработчиков применила метод так называемой дистилляции знаний, включающий создание легкой модели «студента», которая учится на переводах, созданных моделью «учителем» со всеми «фишками» и «наворотами», а не на огромных массивах сырых параллельных данных, на которых обычно тренируют системы машинного перевода. Цель состояла в конструировании модели «студента», которая намного быстрее и менее сложная, чем «учитель», но при условии максимального сохранения качества.
В одном из примеров команда выяснила, что модель «студент» может использовать упрощенный алгоритм декодирования для выбора наилучшего перевода слова на каждом этапе, а не применять обычный метод поиска в огромном пространстве всевозможных вариантов перевода.
Кроме того, исследователи разработали другой подход к парному обучению, использующему преимущества «циклической» проверки перевода. Например, если человек, изучающий японский, хочет проверить правильность написания иероглифа, он может перевести его обратно на английский с помощью переводчика и сразу убедиться, что значение правильно. Алгоритмы машинного обучения также могут обучаться этим способом.
«В исследовательской модели команда использовала парное обучение, что привело к повышению ее мощности. В промышленной модели парное обучение повысило чистоту данных, которые давались потом для обучения модели «студенту». Это достигалось, главным образом, в результате отбрасывания пар предложений, представляющих собой неточный или запутанный перевод, – поясняет Менезес. – Благодаря этому удалось сохранить преимущества данного метода, при этом не затрачивая больших вычислительных ресурсов».
«Методом проб и ошибок команда смогла разработать рецепт, позволяющий модели «студенту» машинного перевода – которая достаточно легко управляется в облачной API – добиться результатов в реальном времени почти таких же точных, как и более сложная модель «учитель»», – продолжает Менезес.

Улучшить результат поиска с помощью многозадачного обучения
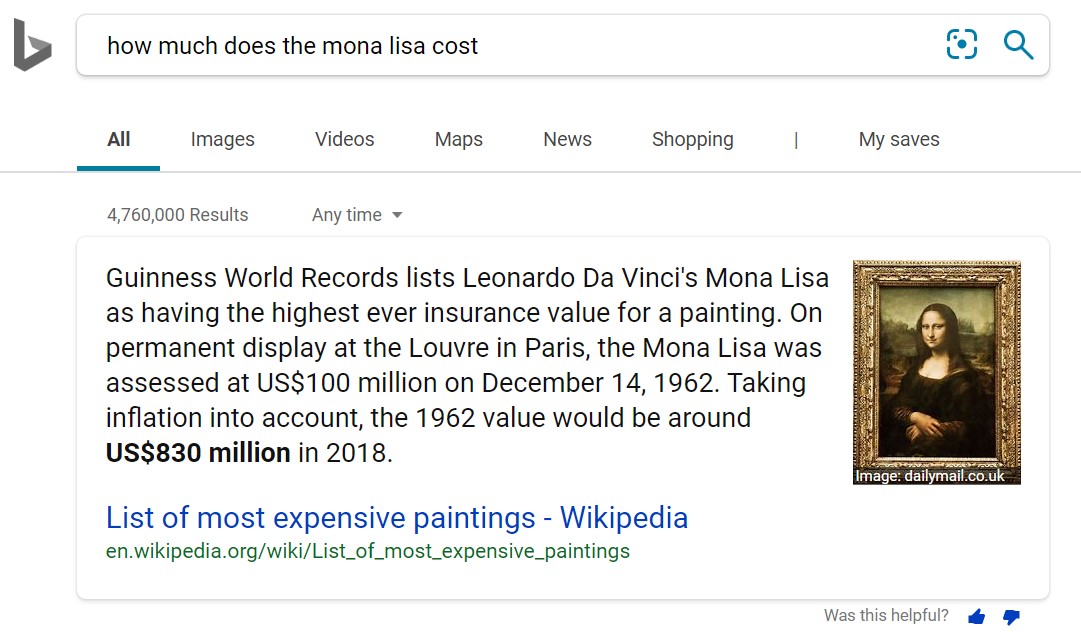
В бурно развивающемся ландшафте ИИ, где постоянно внедряются и совершенствуются новые модели понимания языков, эксперты поискового сервиса Bing тоже не перестают охотиться за новыми перспективными методами. Если в прошлом человек должен был ввести ключевое слово и пройти по нескольким ссылкам, пока он не добрался до искомой информации, то теперь пользователи все больше ищут то, что им нужно, сразу задавая полный вопрос, например: «Сколько стоит Мона Лиза?» или «Укусы какого паука наиболее опасны?»
«Это предоставляет пользователям правильную информацию и позволяет сэкономить время, – говорит Ранган Маджумдер, менеджер партнерской группы программы поиска и ИИ в Bing. – Мы должны сами проделать за них эту работу, подбирая самые авторитетные сайты и выделяя части страниц, которые фактически дают ответ на их вопрос». Чтобы осуществить эту задачу, ИИ-модели должны не только выбрать самые надежные документы, но и показать понимание содержания каждого из них, что требует совершенства в любых аспектах понимания языка.
В прошлом июне исследователи Microsoft первыми разработали модель машинного обучения, которая превзошла человеческий результат по оценке общего понимания языка. Тест измерял мастерство понимания по девяти разным критериям от анализа эмоциональной окраски высказывания и подобия текстов до ответа на вопрос. Решение многозадачных глубоких нейронных сетей (MT-DNN) основано на применении дистилляции знания и многозадачного обучения, позволяющего одну и ту же модель тренировать и обучать сразу на нескольких задачах и переносить знания, полученные в одной области, на другие.
Этой осенью эксперты Bing внедрили основные принципы этого исследования в свои модели машинного обучения, что по их оценкам на 26% улучшило ответы на все вопросы, заданные в Bing в англоязычных странах. Они также улучшили генерацию заголовков статей – или ссылок с ниже идущим описанием – в 20% этих запросов. Многозадачное глубокое обучение привело к самым значительным улучшениям в ответах на вопросы в Bing и заголовках, которые традиционно выполнялись независимо, используя одну модель на обе задачи.
Например, новая модель может ответить на вопрос «Сколько стоит Мона Лиза?» числовой оценкой: 830 млн долл. В ответе ниже сначала модель должна понять, что слово «сколько» предполагает число. Но также она должна понимать контекст вопроса, чтобы предложить современную оценку, а не стоимость 100 млн долл. как было в 1962 г. Посредством многозадачной тренировки команда Bing построила единую модель, которая выбирает наилучший ответ и определяет для себя ключевые слова.
В начале этого года инженеры Bing перевели в разряд открытого исходного кода свои решения для предобучения на больших представлениях языковых данных в Аzure. На том же самом коде инженеры, работающие над Project Turing, разработали свои собственные нейронные языковые представления. Модель общего языкового понимания, которая предобучена понимать ключевые принципы языка, допускает многократное использование для других нижестоящих задач. Она учится заполнять пропуски, если в предложениях отсутствуют отдельные слова.
«Вы берете документ Википедии, удаляете фразу, и модель должна научиться предсказывать, что там должно быть, только по окружающим словам, – говорит Маджумдер. – Совершая это, она обучается синтаксису, семантике, а иногда даже предметной области знаний. Такой подход может затмить что угодно, потому что когда вы настраиваете ее на определенную задачу, она уже владеет большим количеством нюансов языка».
Чтобы натренировать предобученную модели отвечать на вопросы и генерировать заголовки команда Bing применила многозадачный подход, разработанный Microsoft Research для настраивания на множественные задачи сразу.
«Когда модель узнает что-то полезное в результате одной задачи, она может незамедлительно начать применять это к другим областям», – говорит Джианфенг Гао, партнер по исследованиям группы глубокого обучения Microsoft Research.
Например, по его словам, когда человек учится кататься на велосипеде, он должен научиться балансировать, что также может пригодиться ему в катании на лыжах. Уроки езды на велосипеде, таким образом, помогут быстрее овладеть лыжами, по сравнению с человеком без опыта езды на велосипеде.
«В некотором смысле мы заимствуем человеческий подход к обучению. По мере того, как вы все больше набираетесь жизненного опыта, столкнувшись с новой задачей, вы выуживаете полезную ранее приобретенную информацию и применяете ее в новых условиях», – говорит Гао.
Как и команда Microsoft Translator, команда Bing также применяет подход дистилляции знаний. Это позволяет им превратить большую и сложную модель в оптимизированную, которая быстрее работает и достаточно экономична для коммерческого продукта.
Сейчас та же самая модель ИИ, которая применяется в поисковике, используется для улучшения точности ответов на вопросы, когда пользователи ищут информацию внутри своей компании. Если сотрудник вводит вопрос «Могу ли я привести на работу свою собаку?» в интранет своей организации, новая модель осознает, что собака – это домашнее животное, и выдает этому сотруднику положение политики компании по данному вопросу, даже если слово «собака» никогда не фигурировало в тексте. И это дает прямой ответ на поставленный вопрос.
«Так же, как для ответов на запросы в Вing на публичных страницах, мы можем использовать эту же самую модель для понимания вопроса, который вдруг может возникнуть у вас на работе, проанализировать корпоративные документы и предоставить вам ответ», – заключает Маджумдер.
Заглавное фото: инвестиции Microsoft в исследования понимания естественного языка улучшают качество ответов в поисковой системе Bing, например, на такие вопросы, как «Сколько стоит Мона Лиза?». Фото Musée du Louvre/Wikimedia Commons