Con aprendizaje de refuerzo, Microsoft lleva una nueva clase de soluciones de IA a los clientes
 Jennifer Langston
AI Blog
Jennifer Langston
AI Blog
Las preferencias de alguien que busca reservar unas vacaciones en línea hoy tal vez sean muy diferentes a las que tenía antes de la pandemia de COVID-19.
En lugar de volar a una playa exótica, tal vez se sientan más cómodos de conducir a algún lugar cercano. Con opciones limitadas para cenar fuera, tener una cocina completa podría ser esencial. Las habitaciones en moteles o las cabañas podrían ser más atractivas que los hoteles con recepciones compartidas.
Innumerables empresas utilizan motores de recomendaciones en línea para mostrar a los clientes productos o experiencias que coincidan con sus intereses. Y sin embargo, los modelos tradicionales de aprendizaje automático que predicen lo que las personas podrían preferir, a menudo están basados en datos de experiencias pasadas. Esto significa que no necesariamente pueden captar las preferencias de los consumidores, que cambian de manera rápida, a menos que se les vuelva a entrenar con nuevos datos.
Personalizer, que es parte de Azure Cognitive Services dentro de la plataforma Azure AI, usa un enfoque más vanguardista para el aprendizaje automático, llamado aprendizaje de refuerzo, en el que los agentes de IA pueden interactuar y aprender de su entorno en tiempo real.
La técnica fue utilizada en un principio en laboratorios de investigación. Pero ahora, se ha abierto camino en más productos y servicios de Microsoft: desde Azure Cognitive Services que los desarrolladores pueden conectar en aplicaciones y sitios web, a sistemas autónomos que los ingenieros pueden utilizar para refinar los procesos de manufactura. Azure Machine Learning también ha comenzado a mostrar versiones previas de ofertas de aprendizaje de refuerzo basado en la nube para científicos de datos y profesionales del aprendizaje automático.
“Hemos recorrido un largo camino en los últimos dos años, en los que hemos tenido bastantes proyectos de prueba de concepto dentro de Microsoft e implementaciones con algunos clientes”, comentó Rafah Hosn, directora senior del laboratorio de Nueva York de Microsoft Research. “Ahora hemos progresado bastante bien, en cosas que se pueden empaquetar y envolver, y dirigir hacia un conjunto particular de problemas”.

Z-Tech, el centro tecnológico de Anheuser-Busch InBev, utiliza Personalizer para entregar recomendaciones a la medida en un mercado en línea para atender mejor a las tiendas pequeñas de comestibles en México. Otros clientes y socios de Microsoft emplean el aprendizaje de refuerzo para detectar anomalías en la producción y para desarrollar robots que puedan ajustarse a las impredecibles condiciones del mundo real: con modelos que pueden aprender de pistas ambientales, a la retroalimentación de expertos o al comportamiento del consumidor en tiempo real.
Una vez que Microsoft comenzó a utilizar Personalizer en su página de inicio para personalizar a nivel contextual los productos desplegados para cada visitante, la compañía vio un incremento de 19 veces en el compromiso con los productos que Personalizer elegía. La empresa también utilizó Personalizer de manera interna, para seleccionar las ofertas, productos y contenido correctos a través de Windows, el navegador Edge y Xbox. Estos escenarios han dado un incremento del 60% en involucramiento a través de miles de millones de personalizaciones cada mes.
Teams también ha utilizado aprendizaje de refuerzo para encontrar el búfer óptimo de fluctuación para una reunión en video, que compensa los retratos de información a escala de milisegundos, para brindar una mejor continuidad de la conexión, mientras que Azure explora la optimización basada en aprendizaje de refuerzo para ayudar a determinar cuándo reiniciar o corregir máquinas virtuales.
Debido a que los modelos de aprendizaje de refuerzo aprenden de la retroalimentación instantánea, pueden adaptarse de manera rápida a circunstancias cambiantes o impredecibles. Cuando golpeó la pandemia de COVID-19, algunas empresas no tenían idea de qué esperar, ya que los comportamientos de compra y viaje de las personas cambiaron de la noche a la mañana, comentó Jeff Mandenhall, director de programas para Personalizer en Microsoft.
“Todo su modelado histórico y conocimiento experto salieron por la ventana”, comentó Mendenhall. “Pero con el aprendizaje de refuerzo, Personalizer puede actualizar el modelo cada minuto, de ser necesario, para aprender y responder a cómo son los comportamientos actuales del usuario”.
En el aprendizaje de refuerzo, un agente de IA aprende en gran medida por prueba y error. Prueba diferentes acciones en un mundo real o en uno simulado, y obtiene una recompensa cuando las acciones alcanzan un resultado deseado, ya sea que un cliente oprima el botón para reservar vacaciones o que un robot descargue con éxito una bolsa de monedas difícil de manejar.
Entrenar a un agente de IA a través del aprendizaje de refuerzo es similar a enseñar a un cachorro a que haga un truco, comentó Hosn. Recibe un premio cuando toma decisiones que producen el resultado deseado y aprende a repetir las acciones que obtienen más premios. Pero en escenarios complicados del mundo real, explorar el vasto universo de acciones potenciales y encontrar una secuencia óptima de decisiones, puede ser mucho más complicado.
En la 34 Conferencia de Sistemas de Procesamiento de Información Neural (NeurIPS 2020), realizada hace unos días, los investigadores de Microsoft presentaron 17 documentos de investigación que marcan un progreso significativo en hacer frente a algunos de los más grandes desafíos de este campo. Al invertir en equipos de aprendizaje de refuerzo a través de su red de laboratorios Microsoft Research, la empresa dice que desarrolla una cartera de enfoques para afrontar diferentes problemas y explorar múltiples rutas para avances potenciales.

Esos equipos se han enfocado en desarrollar un robusto entendimiento de elementos fundamentales del aprendizaje de refuerzo y en crear soluciones prácticas para los clientes: no sólo demostraciones novedosas, comentaron los investigadores.
Han dedicado mucho tiempo en averiguar qué escenarios son adecuados para resolver el aprendizaje de refuerzo, así como a investigar los fundamentos técnicos para entender por qué algo funciona y cómo repetirlo, comentó John Langford, gerente asociado de investigación en Microsoft Research Lab – Nueva York.
“Justo ahora, hay una gran brecha entre las aplicaciones únicas en las que puedes hacer que los doctores trabajen muy duro y descubran una manera de hacerlo funcionar, en lugar de desarrollar un sistema útil de manera rutinaria, que pueda ser usado una y otra vez”, comentó Langford.
“Toda nuestra investigación sobre aprendizaje de refuerzo en Microsoft en realidad cae en dos grandes contenedores: ¿Cómo podemos resolver desafíos que los clientes nos traen y cuáles son las bases que podemos usar para construir soluciones replicables y confiables”, mencionó.
Un enfoque diferente hacia el aprendizaje automático
El aprendizaje de refuerzo utiliza un enfoque que es diferente, de manera fundamental, al del aprendizaje supervisado, una técnica más común del aprendizaje automático en el que los modelos aprenden a hacer predicciones a partir de ser alimentados por ejemplos de entrenamiento.
Si una persona intenta aprender francés, exponerse a textos, reglas gramaticales y vocabulario en francés, es más cercano a un enfoque de aprendizaje supervisado, comentó Raluca Georgescu, ingeniera de investigación de software que trabaja en Project Paidia, en el laboratorio de Cambridge de Microsoft Research en Reino Unido.
Con un enfoque de aprendizaje de refuerzo, irían a Francia y aprenderían al hablar con la gente. Serían penalizados con miradas de duda si dicen algo mal y serían recompensados con un croissant si lo ordenan de manera correcta, comentó.
Un agente de aprendizaje de refuerzo aprende de interactuar con su entorno, ya sea en el mundo real o en un ambiente simulado que le permite explorar diferentes opciones de manera segura. Toma una acción y espera a ver si resulta en algo positivo o negativo, basado en un sistema de recompensa que ha sido establecido. Una vez que se ha recibido la retroalimentación, el modelo aprende si la decisión fue buena o mala y se actualiza de acuerdo con esto.
Es una forma en verdad simple de aprender, que es endémica en el mundo natural, comentó Langford.
“Incluso los gusanos pueden hacer aprendizaje de refuerzo: pueden aprender a ir hacia algo o evitarlo con base en algo de retroalimentación”, mencionó Langford. “La capacidad de aprender a un nivel muy básico, a partir de tu entorno, es algo que es muy natural para nosotros, pero en el aprendizaje automático es un poco más complicado y delicado, y requiere de más reflexión que el aprendizaje supervisado”.
Los nuevos documentos presentados en NeurIPS ofrecen contribuciones significativas en tres áreas clave de investigación: aprendizaje de refuerzo por lotes, exploración estratégica con observaciones ricas y aprendizaje de representación. En conjunto, dicen los investigadores, estos avances apuntan a impulsar la eficiencia de los modelos y expandir el alcance de los problemas que puede resolver el aprendizaje de refuerzo.
De laboratorios de investigación a productos del mundo real
Personalizer, el primer Azure Cognitive Service en ser construido sobre aprendizaje de refuerzo, surgió de una estrecha colaboración entre investigadores de Microsoft y expertos de producto de Azure. Ellos querían ayudar a los desarrolladores a ofrecer con facilidad el contenido adecuado a los usuarios correctos, en el momento adecuado, sin requerir de un conocimiento profundo de aprendizaje automático.
Metrics Advisor, un nuevo Azure Cognitive Service ahora disponible en versión previa pública, también utiliza aprendizaje de refuerzo para incorporar retroalimentación y hacer que los modelos se adapten mejor al conjunto de datos del cliente, lo que ayuda a detectar anomalías más sutiles en sensores, procesos de producción o métricas de negocios.
De manera automática, Personalizer selecciona qué mostrar a alguien que mira un sitio web o qué pregunta debería hacer un chatbot a continuación para llevar a un resultado de negocios o de experiencia deseado. Esto podría ser lograr que una persona se comprometa con hábitos alimenticios más saludables o tratar una nueva experiencia de videojuegos. El agente aprende a través de prueba y error qué contenido es más útil o persuasivo para diferentes tipos de usuarios.
Al intentar hacer una recomendación de video, por ejemplo, lo que alguien prefiere ver podría estar impulsado por la hora del día, si está sentado en casa o en movimiento, o por cuánta batería le queda a su dispositivo. Personalizer aprende de las elecciones o acciones que han realizado clientes con características similares.

Z-Tech, el centro tecnológico de la empresa multinacional de bebidas y cerveza AB InBev, comenzó a utilizar Personalizer este otoño para entregar recomendaciones personalizadas a las tiendas de abarrotes familiares en México, que realizan sus pedidos a través del mercado en línea MiMercado. Ha visto un incremento de casi el 100% en las tasas de clic para los productos personalizados y un incremento del 67% en la conversión del interés de los clientes en pedidos.
“A medida que aprendíamos de las capacidades de la plataforma Azure, Personalizer apareció como algo que es muy avanzado e innovador, y resolvió una necesidad para nosotros”, comentó Luiz Gondim, director global de tecnología para Z-Tech, cuyo objetivo es llevar soluciones impulsadas por datos a negocios pequeños y medianos.
En el pasado, los productos presentados en MiMercado eran los mismos para todos los clientes. Z-Tech estaba interesado en utilizar IA para hacer recomendaciones personalizadas y más útiles para una tienda individual de la esquina que vende de todo, desde cerveza y suministros para hornear, a botanas y alimento para mascotas.
Personalizer tuvo dos beneficios diferenciadores, comentó Richard Sheng, director global de ciencia de los datos y analítica para Z-Tech.
“Por su propia naturaleza, los modelos de aprendizaje de refuerzo por lo general requieren de menos datos porque usan el contexto actual para generar recomendaciones y aprender a través de la retroalimentación del usuario”, comentó. “Y tener los modelos ya desarrollados y envueltos en una API que podemos usar en esta forma tipo conectar y usar, fue de gran ayuda”.
Los investigadores de sistemas autónomos de Microsoft colaboraron con científicos e ingenieros de Sber, una empresa global de servicios financieros y tecnología que opera SberBank, el banco más grande en Rusia, Europa Central y del Este, y una de las instituciones financieras líderes a nivel mundial, para que usara aprendizaje de refuerzo para desarrollar tecnologías robóticas para descargar pesadas bolsas recolectoras de monedas de carros móviles, para que puedan ser contadas y vueltas a empaquetar.
En un documento de reciente publicación que describe esos resultados, los investigadores detallaron cómo manipular bolsas inestables de monedas, con un centro de gravedad en constante cambio, es un problema más complicado de robótica que tomar objetos sólidos. Es el tipo de escenario que es un lugar común en el mundo físico, pero que los robots que dependen de sistemas tradicionales de control o de redes neurales batallan por dominar, comentó Albert Efimov, vicepresidente de investigación e innovación en SberBank.
“Vimos una oportunidad de en verdad avanzar la ciencia y usar el aprendizaje de refuerzo para enseñar a una máquina a desempeñar un proceso bastante difícil”, comentó Efimov. “La bolsa tiene una forma impredecible y amorfa, e incluso los seres humanos tienen que pensar un momento en cómo manejarla. Para un robot hacer esto es un gran problema”.
El equipo de Sber y Microsoft utilizó aprendizaje profundo de refuerzo y técnicas de enseñanza automática para primero entrenar al agente de IA en un ambiente simulado, donde pudiera explorar diferentes estrategias y aprender qué funcionaba mejor. Una vez desplegado en condiciones de trabajo del mundo real, el sistema robótico pudo descargar con éxito las bolsas de monedas en el primer intento el 95% del tiempo.
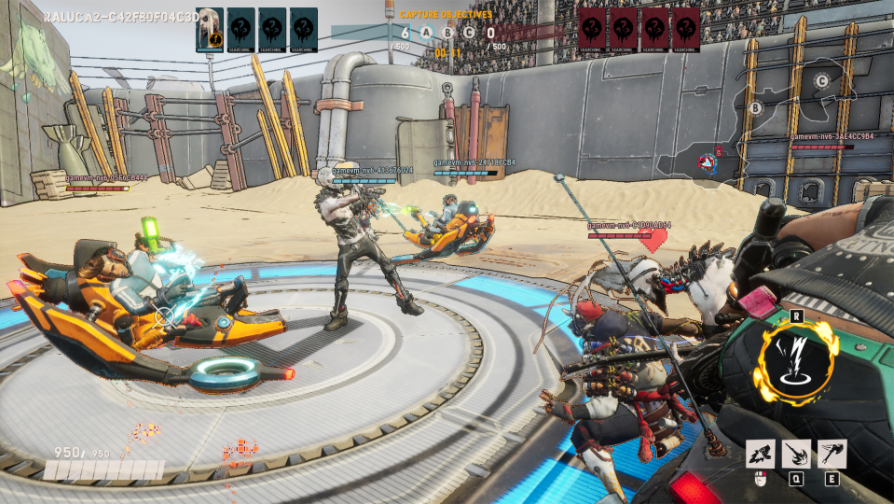
En Project Paidia, investigadores del laboratorio de Reino Unido-Cambridge de Microsoft Research, colaboran con Ninja Theory, un estudio de juegos de Xbox. La meta es impulsar la investigación de vanguardia en el aprendizaje de refuerzo que pueda permitir nuevas aplicaciones en videojuegos modernos, y desarrollar agentes de IA que puedan aprender para colaborar con jugadores humanos.
Los agentes que usan el aprendizaje de refuerzo tienen el potencial de anticipar mejor los comportamientos y reaccionar a matices, para habilitar una colaboración efectiva con jugadores humanos que son creativos e impredecibles, y tienen diferentes estilos de juego, comentó Katja Hofmann, investigadora principal quien lidera un equipo que se enfoca en aprendizaje profundo de refuerzo en videojuegos y otras áreas de aplicación en el laboratorio de Cambridge-Reino Unido de Microsoft Research. Los bots desarrollados con tecnologías actuales batallan para navegar por esas complejidades y no reaccionan de la misma manera en que la gente lo hace.

Videojuegos como Bleeding Edge, de Ninja Theory, que requiere de personajes con diferentes personalidades y superpoderes para hacer equipo y conseguir puntos y derrotar oponentes, ofrece un útil banco de pruebas para el desarrollo de agentes de IA que puedan usar el aprendizaje de refuerzo para coordinar acciones y reaccionar de manera apropiada a nuevas situaciones a través de una serie de recompensas.
“Tener un bot que pueda colaborar de manera genuina con jugadores humanos es considerado imposible con la tecnología IA de los juegos tradicionales, así que esto crea un espacio en verdad agradable para nosotros”, comentó Hoffmann. “Si podemos demostrar cómo hacer esto en los videojuegos, es un primer paso para demostrar cómo podemos crear agentes fuera de los videojuegos que puedan trabajar de manera colaborativa con los seres humanos en otras formas”.
El equipo de investigación de Project Paidia y otros en Microsoft ayudaron a Azure Machine Learning a entender lo que en realidad necesitan los usuarios intensivos del aprendizaje de refuerzo en términos de infraestructura y poder de cómputo.
Han desarrollado herramientas que permiten a las personas experimentar con la tecnología, incluida una demo que permite a la gente jugar un juego sencillo con un agente de aprendizaje de refuerzo para ver cómo reacciona, así como libretas de muestra de Azure Machine Learning para crear un agente que pueda navegar por un laberinto de lava en Minecraft.
Grandes empresas en los campos industrial, de manufactura y de servicios financieros que emplean a científicos de datos con experiencia en aprendizaje de refuerzo ahora usan las ofertas de aprendizaje de refuerzo de Azure Machine Learning, presentadas a inicios de 2020, para poner en marcha y manejar procesos de entrenamiento en la nube, comentó Keiji Kanazawa, director de programa en Microsoft.
“Para los clientes que llevan a cabo prueba y error a gran escala, el valor de la nube es que lo pueden hacer de manera masiva”, comentó. “Nuestras herramientas permiten a los clientes enfocarse en lo que tratan de hacer con aprendizaje de refuerzo y sus metas y la estructura de las recompensas y todo el cómputo, tan solo suceden en el back-end”
Imagen principal: Investigadores de Microsoft y Sber utilizaron aprendizaje de refuerzo para desarrollar una tecnología robótica que pueda descargar bolsas de monedas de difícil manejo de carros móviles. Foto cortesía de Sber.
Contenido relacionado:
- Conozcan más: NeurIPS 2020: Moverse hacia el aprendizaje de refuerzo del mundo real a través de RL de lote, exploración estratégica y aprendizaje de representación
- Conozcan más: Sber y Microsoft desarrollan un robot de IA de sistema de control único
- Conozcan más: La historia del aprendizaje de refuerzo en Microsoft Research
- Conozcan más: Personalizer
- Conozcan más: Metrics Advisor
- Conozcan más: Azure Cognitive Services
- Conozcan más: Azure Machine Learning Reinforcement Learning
- Conozcan más: Sistemas autónomos
- Conozcan más: Project Paidia
Jennifer Langston escribe sobre investigación e innovación de Microsoft. Síganla en Twitter.