La innovación detrás de la IA a Escala
En la publicación de blog Desmitificar la IA a Escala, brindamos una descripción general rápida de cómo Microsoft y un número cada vez mayor de nuestros clientes aprovechan la tendencia de los modelos de IA a gran escala para admitir una variedad de aplicaciones. Creemos que todas las organizaciones del mundo deberían beneficiarse del poder de estos modelos, razón por la cual la iniciativa IA a Escala de Microsoft hace que estos grandes modelos, y los sistemas y la infraestructura para permitir la capacitación y la utilización, estén disponibles como una plataforma.
El impulso de esta iniciativa es la investigación de vanguardia de Microsoft sobre IA, guiada por aplicaciones y escenarios del mundo real. Microsoft Research ha estado a la vanguardia de los avances de la IA con avances en el procesamiento del lenguaje natural, la visión por computadora, el reconocimiento de voz y más. En 2018, inspirados por los primeros desarrollos de investigación en el espacio de modelos de lenguaje grande, comenzamos a utilizar estos modelos a gran escala en servicios que van desde Microsoft Bing hasta Microsoft 365. Los resultados fueron en extremo prometedores. Sin embargo, estaba claro que la mayoría de las organizaciones encontrarían nuestros resultados difíciles de duplicar debido a barreras como el acceso a infraestructura a gran escala.
Entonces, decidimos desarrollar plataformas, herramientas y una infraestructura de supercomputación que permitiera a cualquier desarrollador construir y escalar su propia innovación de IA. En la conferencia de desarrolladores Microsoft Build 2020, anunciamos la iniciativa Microsoft IA a Escala, dedicada a brindar a todas las organizaciones acceso a estos poderosos modelos de IA.
Desde entonces, el progreso continuo en la investigación de IA fundamental y aplicada se ha traducido en productos, servicios y operaciones cada vez más transformadores, que Microsoft se compromete a hacer accesibles para todos.
Esta publicación de blog explora las innovaciones detrás de la iniciativa Microsoft IA a Escala.
Productos y servicios de Microsoft mejorados con IA
Todos los días, millones de personas se benefician de los poderosos modelos básicos a gran escala de Microsoft disponibles en más de 80 escenarios empresariales y de consumo. Por ejemplo, nuestra capacidad de comprensión de idiomas les permite usar el lenguaje natural para encontrar respuestas relevantes a preguntas de dominio abierto en 100 idiomas a través de Bing o dentro de Microsoft Word. Con la misma tecnología IA a Escala, Microsoft Dynamics 365 brinda respuestas, conocimientos y acciones relevantes que los empleados pueden tomar para sus propias operaciones comerciales.
Gracias a la generación de idiomas, la Respuesta Sugerida hace que la mensajería instantánea en Microsoft Outlook y Microsoft Teams sea una experiencia más rica. Con Microsoft Editor, los escritores pueden usar herramientas inteligentes para crear una prosa más pulida. Nuestro modelo de generación de lenguaje también es capaz de conocer y sintetizar código de software. Viva Topics organiza de manera automática el contenido y la experiencia en una organización, lo que facilita que las personas encuentren información y pongan el conocimiento a trabajar, mientras que GitHub Copilot ayuda a los desarrolladores a convertir el lenguaje natural en código a través de OpenAI Codex.
Funciones que utilizan IA a Escala
Más allá de los modelos de lenguaje, la inteligencia multimodal en texto, imagen y diseño permite hermosas recomendaciones de diseño de diapositivas en Microsoft PowerPoint Designer. Esta capacidad multimodal puede encontrar respuestas relevantes en lenguaje natural, visualizar la respuesta presentada en imágenes y refinar la búsqueda con objetos visuales a partir de imágenes en las experiencias de búsqueda multimedia y de preguntas y respuestas de Bing.
Pila tecnológica de IA a Escala
La misma pila de IA a Escala utilizada en los productos y servicios de Microsoft está disponible para las organizaciones a través de Microsoft Azure. Antes de explorar cómo pueden crear este tipo de experiencias dentro de sus propios productos y servicios, profundicemos en los componentes de la pila.
APIs
Una de las formas más sencillas de usar estos poderosos modelos entrenados de manera previa es a través de una API administrada. Los modelos de Microsoft están disponibles como terminales de API a través de Azure Cognitive Services, Azure OpenAI Service y Azure Cognitive Search. Esto les da acceso a los modelos sin tener que preocuparse por la infraestructura y los detalles de alojamiento.
Azure Cognitive Services
Azure Cognitive Services son servicios basados en la nube con API REST y SDK de biblioteca de cliente para ayudar a los desarrolladores a incorporar inteligencia cognitiva en las aplicaciones. Esto les permite crear soluciones cognitivas que pueden ver, oír, hablar, comprender e incluso tomar decisiones.
- Azure Cognitive Services for Language proporciona API para varias tareas posteriores, como la traducción automática, el análisis de opiniones, el reconocimiento de entidades con nombre y el resumen de texto, lo que proporciona un fácil acceso a nuestros modelos de lenguaje a gran escala.
- Azure Cognitive Services para tareas de voz y visión proporciona API para tareas visuales y multimodales, como preguntas y respuestas visuales, subtítulos de imágenes, detección de objetos y reconocimiento y traducción de voz.
- Ajusten su modelo para su dominio o datos con API como clasificación de texto personalizada, visión personalizada y reconocimiento de entidad con nombre personalizado.
Azure OpenAI Service
Azure OpenAI Service, que en la actualidad se encuentra en versión preliminar privada, brindará a las organizaciones acceso al poderoso modelo de generación de lenguaje natural GPT-3 de OpenAI, con la seguridad, la confiabilidad y las capacidades empresariales de Azure. Algunos de los primeros clientes han comenzado a utilizar el servicio de forma creativa.
Azure Cognitive Search
La búsqueda semántica, que se ofrece a través de Azure Cognitive Search, es una capacidad relacionada con consultas que aporta relevancia semántica y comprensión del lenguaje a los resultados de búsqueda. Organizaciones como Igloo Software y Ecolab lo utilizan para impulsar a clientes y empleados por igual. Cuando está habilitada en su servicio de búsqueda, la búsqueda semántica amplía la canalización de ejecución de consultas de dos maneras: agrega una clasificación secundaria sobre un conjunto de resultados inicial, promueve los resultados más relevantes desde el punto de vista semántico a la parte superior de las listas; y extrae y devuelve subtítulos y respuestas, que puede representar en una página de búsqueda.
Modelos IA entrenados de manera previa
Aprovechamos nuestra ya sólida colaboración entre la investigación y la ingeniería para lograr nuevas técnicas de modelado para avances lingüísticos e integrarlos de manera continua en nuestra familia de modelos básicos a gran escala. Por ejemplo, el avance de las técnicas de aprendizaje auto supervisado permite que los sistemas de IA aprendan de órdenes de magnitud de más datos, diferentes idiomas de datos y diferentes modalidades de datos, lo que permite modelos mucho más grandes y precisos. A continuación, se presentan algunos logros emocionantes.
Entendimiento del lenguaje natural
Nuestra familia de modelos básicos a gran escala comenzó con modelos monolingües para la comprensión del lenguaje. Microsoft fue la primera empresa que superó la paridad humana en el punto de referencia SuperGLUE al incorporar a DeBERTa, que se integró en el modelo Turing NLRv4. La capacidad de comprensión del idioma fue superada por el modelo Turing NLRv5, que de manera reciente se convirtió en el nuevo líder en las tablas de clasificación GLUE y SuperGLUE. Al ampliar la capacitación del modelo para admitir varios idiomas, el modelo multilingüe Turing ULRv5, con soporte para 100 idiomas, alcanzó la cima de la tabla de clasificación XTREME, un punto de referencia para evaluar la comprensión de idiomas multilingües.
Aunque estos modelos lingüísticos pre-entrenados a gran escala han logrado avances significativos en la comprensión del lenguaje, todavía tienen dificultades con el conocimiento de sentido común que se acumula en nuestra vida diaria. Microsoft KEAR logró este avance en el sentido común que superó la paridad humana en el punto de referencia CommonsenseQA en diciembre de 2021.
Generación de lenguaje natural
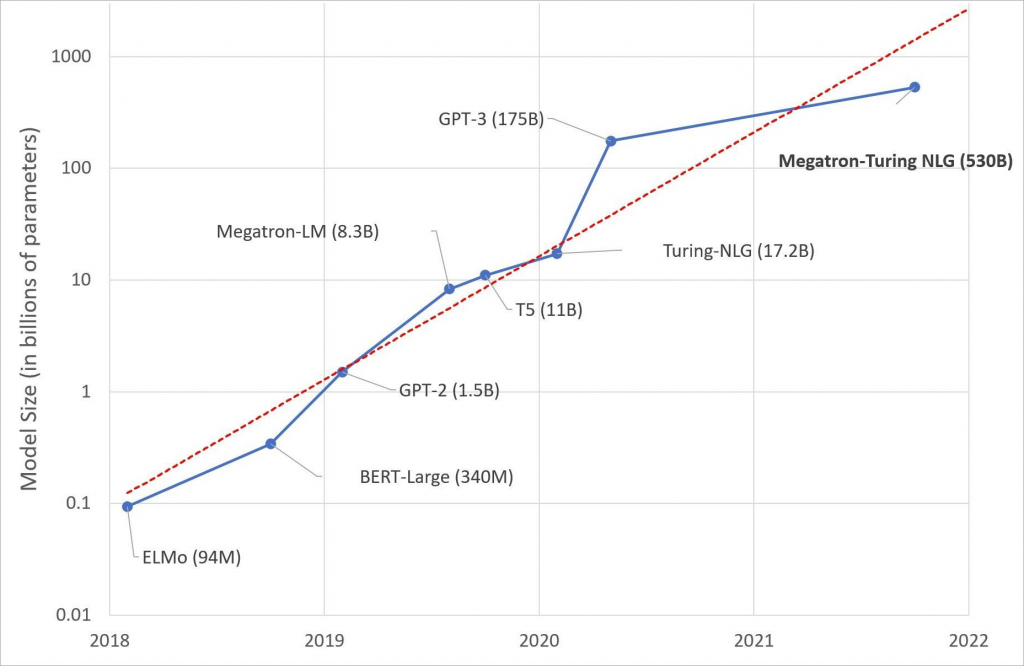
En febrero de 2020, Microsoft anunció Turing Natural Language Generation (T-NLG), el modelo más grande jamás publicado en ese momento, con 17 mil millones de parámetros. Superó a los modelos de última generación en una variedad de puntos de referencia de modelado de lenguaje en tareas como resúmenes y preguntas y respuestas. Esto sentó las bases para la capacidad de la plataforma que nos permite entrenar modelos cada vez más grandes.
El año pasado, nuestra asociación con OpenAI trajo a la corriente principal los modelos GPT-3 que iluminan las experiencias de productos innovadores, como la creación de aplicaciones sin código o con código bajo a través de la conversación con el código en Microsoft Power Apps. Luego ampliamos esta capacidad generativa a 100 idiomas con un modelo de codificador-decodificador generativo multilingüe unificado (Turing ULG) que aporta innovación en investigación y DeltaLM. Este modelo encabeza la clasificación en el desafío de Traducción Automática Multilingüe a gran escala.
En 2021, a través de la asociación de Microsoft con NVIDIA, anunciamos el modelo Turing Natural Language Generation (MT-NLG), el modelo de lenguaje generativo más grande del mundo. Al empujar los límites en la escala del modelo, logra un alto nivel de precisión en las principales categorías de tareas de lenguaje natural, incluido el razonamiento de sentido común, la comprensión de lectura, la predicción de texto y la inferencia del lenguaje en el entorno de cero, uno y pocos disparos. sin buscar tomas óptimas.
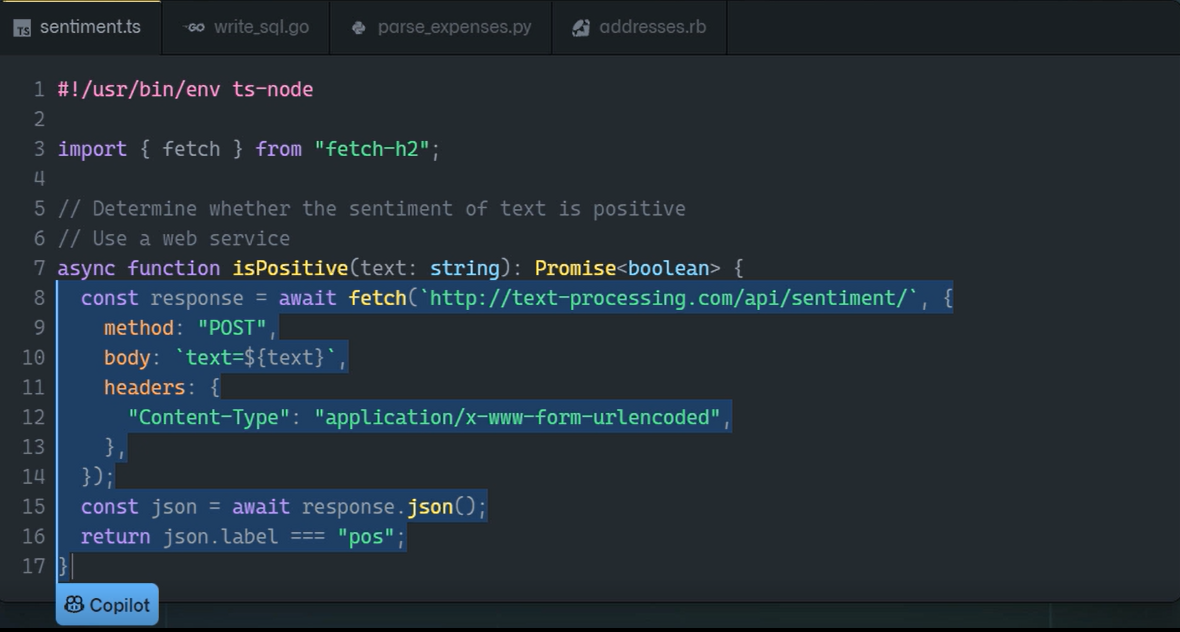
Generación de lenguaje a código
En términos de un lenguaje de máquina simbólico más estructurado, el modelo de Codex amplió el GPT-3 de la generación de lenguaje natural a la generación de código a través de entrenar en miles de millones de líneas de código fuente y texto en lenguaje natural para potenciar GitHub Copilot, un nuevo programador de pares de IA que te ayuda a escribir mejor código.
Multimodal
Dado el gran avance en los poderosos modelos lingüísticos a gran escala, entendimos que era fundamental incorporar otras modalidades a nuestros modelos. Estos modelos multimodales pueden razonar de manera conjunta en múltiples formatos de entrada, incluidos texto, diseño, imágenes y video.
Nuestro nuevo modelo Vision-Language superó los puntos de referencia de NoCaps al superar las líneas de base humanas. Y nuestro modelo de representación de lenguaje de imagen universal de Turing Bletchley de 2,500 millones de parámetros logra un rendimiento sobresaliente en tareas de lenguaje de imagen en 94 idiomas. Incluso comprende texto en imágenes sin usar tecnologías OCR, al identificar de manera directa imágenes similares con vector de imagen codificada. Además, entrenamos un modelo básico de visión por computadora, llamado Florence V1.0, que logra un rendimiento de última generación para una amplia gama de tareas de visión por computadora que cubren más de 40 puntos de referencia.
Un enfoque importante para mejorar las capacidades de los modelos es la formación de modelos expertos con subtareas mediante un método de conjunto, denominado Mixture of Experts (MoE). La arquitectura MoE también conserva el cálculo sublineal con respecto a los parámetros del modelo, lo que proporciona un camino prometedor para mejorar la calidad del modelo al escalar trillones de parámetros sin aumentar el costo de capacitación. También hemos desarrollado modelos MoE para nuestra familia de modelos pre-entrenados acelerados con DeepSpeed. (Los detalles de DeepSpeed se pueden encontrar a continuación).
Estos modelos pre-entrenados a gran escala se convierten en plataformas y se pueden adaptar a dominios o tareas específicos mediante el uso de datos específicos del dominio de manera compatible con la privacidad. Nos referimos a esta colección de modelos básicos y adaptados al dominio como “modelos de IA como plataforma”, que se pueden usar de manera directa para crear nuevas experiencias con aprendizaje de disparo cero/pocos disparos o se pueden usar para crear modelos más específicos de tareas a través de la proceso de ajuste fino del modelo con un conjunto de datos etiquetado para la tarea. De manera similar, pueden adaptar o afinar estos modelos de dominio con sus propios datos empresariales de forma privada dentro del alcance de su tenant y usarlos en sus aplicaciones empresariales para aprender representaciones y conceptos exclusivos de su negocio y productos.
Servicio Azure Machine Learning
El servicio Azure Machine Learning es el servicio de nivel empresarial en la nube de Azure que admite el ciclo de vida de desarrollo de aprendizaje automático de un extremo a otro. Proporciona una experiencia con una alta productividad para construir, entrenar e implementar modelos de aprendizaje automático y aprendizaje profundo más rápido a escala. Permite la colaboración en equipo con seguimiento de experimentos, recopilación de métricas de rendimiento de modelos y MLOps (DevOps para aprendizaje automático) líderes en la industria. El servicio Azure Machine Learning admite el entrenamiento y la implementación de modelos en todos los principales marcos y tiempos de ejecución de aprendizaje profundo, como nuestro ONNX Runtime optimizado. El servicio Azure Machine Learning permite el uso efectivo de la infraestructura subyacente de Azure AI y las optimizaciones del sistema.
Software de aceleración de aprendizaje automático
Los modelos grandes con miles de millones o incluso billones de parámetros requieren una gran cantidad de estrategias de optimización y paralelización para entrenarse de manera eficiente. Por lo tanto, desarrollamos un conjunto de técnicas de optimización, como Zero Redundancy Optimizer (ZeRO), y las convertimos en fuente abierta en una biblioteca de aceleración de PyTorch llamada DeepSpeed desde 2020. DeepSpeed se mantiene como la pionera con un enfoque extremo en la velocidad, la escala, la eficiencia y la facilidad de uso, y la democratización del entrenamiento e inferencia de modelos a gran escala.
Algunas de las nuevas funciones de DeepSpeed incluyen la capacidad de entrenar de manera eficiente modelos dispersos a través de la técnica de aprendizaje automático MoE, mayor eficiencia de datos y estabilidad de entrenamiento a través del aprendizaje del plan de estudios, inferencia distribuida rápida y eficiente para modelos grandes y biblioteca de kernel de GPU de alto rendimiento especializada para operadores utilizados de manera amplia, como transformadores estándar y dispersos.
ZeRO-Infinity es otra característica de DeepSpeed. Rompe el muro de la memoria de la GPU para permitir el entrenamiento de modelos con billones de parámetros mediante la descarga de parámetros y estados al almacenamiento en disco NVMe, lo que le permite entrenar modelos grandes en una sola GPU o un solo nodo con algunas GPU. Por ejemplo, puede ajustar un modelo de tamaño GPT-3 en un solo nodo gracias a ZeRO-Infinity para crear la capacidad de entrenar modelos muy grandes en hardware más modesto. Con las optimizaciones de DeepSpeed, nuestras cargas de trabajo de producción internas han visto una escala de modelo de 2 a 20 veces más grande y un entrenamiento rápido para modelos grandes.
El siguiente video muestra cómo ZeRO-Infinity aprovecha de manera eficiente la GPU, la CPU y NVMe al 1) dividir cada capa del modelo en todos los procesos de datos, 2) colocar las particiones en los dispositivos NVMe paralelos de datos correspondientes y 3) coordinar el movimiento de datos necesario para calcular propagación hacia adelante/hacia atrás y actualizaciones de peso en las GPU y CPU paralelas de datos, de manera respectiva.
ONNX Runtime (ORT) es otra dimensión en la optimización tanto para el entrenamiento como para la inferencia donde compilamos gráficos de ejecución de modelos de aprendizaje profundo y determinamos la ejecución óptima mediante la fusión de operadores y una biblioteca de núcleos de GPU de una alta eficiencia. Ahora, pueden combinar las optimizaciones de ejecución a nivel de gráficos de ONNX Runtime y las optimizaciones algorítmicas en DeepSpeed, a través del módulo Torch ORT que Microsoft contribuyó al código abierto PyTorch, lo que hace que la capacitación sea aún más eficiente. En nuestras pruebas comparativas, notamos una mejora del 86% en el rendimiento para ajustar con precisión los modelos Hugging Face cuando se combinaron DeepSpeed y ORT.
Estamos encantados de ver que algunos de los marcos y bibliotecas líderes, como PyTorch Lightning, FairScale y Hugging Face, adoptan DeepSpeed y ORT. DeepSpeed también fue fundamental para la colaboración de Microsoft con NVIDIA en el entrenamiento del modelo de lenguaje más grande del mundo, un modelo de 530 mil millones de parámetros. Iniciativas como BigScience Workshop aprovechan la tecnología DeepSpeed para construir modelos multitarea multilingües a gran escala con un enfoque basado en la comunidad abierto a nivel global.
Desde hace varios años, ONNX Runtime ha sido compatible con la inferencia tanto en CPU como en GPU, lo que ofrece una velocidad de hasta 17 veces a través de optimizaciones integradas. Ampliamos las optimizaciones para cubrir la implementación de modelos más allá de la nube y dispositivos perimetrales basados en PC para incluir ONNX Runtime para dispositivos móviles y ONNX Runtime para la web para ejecutar modelos de inferencia a nivel local en dispositivos Android e iOS o en un navegador web con poca memoria y huella de almacenamiento.
También desarrollamos otras innovaciones algorítmicas, como la Adaptación de Bajo Rango de Lenguaje Grande (LoRA, por sus siglas en inglés), que ayuda a reducir aún más la huella de memoria mientras ajusta modelos grandes al tener que volver a entrenar solo un pequeño subconjunto de los parámetros (10 mil veces más bajo en algunos casos) en lugar de todos los parámetros en el proceso de ajuste fino, lo que ahorra 3 veces en requisitos de cómputo. De manera similar, LoRA es útil en la implementación de varias instancias independientes de modelos ajustados basados en el mismo modelo pre-entrenado grande que comparte los parámetros del modelo base y tiene un pequeño subconjunto de parámetros para cada instancia o tarea posterior.
Estas innovaciones han permitido el uso eficiente de los recursos informáticos para permitir la capacitación con menos recursos y permitir que los investigadores experimenten con modelos aún más grandes para avanzar en el estado del arte para diversas tareas y sin arruinarse.
Infraestructura
Por último, construir IA a gran escala requiere una infraestructura escalable, confiable y de alto rendimiento. Azure ofrece la mejor infraestructura de supercomputación de su clase en la nube pública para cargas de trabajo de IA de todos los tamaños. Admite la aceleración de GPU para marcos populares como TensorFlow, PyTorch y otros desde una sola GPU hasta la máquina virtual insignia de la serie NDv4, que ofrece ocho GPU NVIDIA A100-80GB interconectadas por completo por las redes más rápidas dentro y entre las máquinas. Este sistema está clasificado en la actualidad en la lista de las 10 mejores supercomputadoras más rápidas del mundo y es el primer sistema público basado en la nube en esta lista. Además de estos recursos informáticos de IA, Azure también ofrece una amplia gama de soluciones de almacenamiento y redes esenciales para las cargas de trabajo de capacitación de IA.

Ver hacia adelante
La escala de los modelos de IA continúa en aumento, habilita capacidades que antes parecían imposibles y da como resultado registros de referencia de última generación. Las capacidades de hardware e infraestructura seguirán el ritmo de crecimiento. A medida que las técnicas, como MoE, maduren aún más en términos de herramientas y eficiencia, veremos más avances en IA a Escala, incluido un aumento en modelos únicos entrenados en diversos conjuntos de datos para realizar múltiples tareas a escala.
Y la misma energía que vimos en torno a los modelos de lenguaje grande se ha extendido a otros dominios, como la visión por computadora, el aprendizaje de gráficos y el aprendizaje por refuerzo. Los modelos serán de naturaleza cada vez más multimodal, aprenden representaciones a través de múltiples formatos de entrada a través de combinaciones de audio, imágenes, video, lenguaje, datos tabulares estructurados, datos gráficos y código fuente para brindar experiencias más ricas.
Continuaremos con el ofrecimiento de más de estos poderosos modelos de IA como plataforma para clientes y socios a través de nuestros diferentes canales, ya sea a través de experiencias integradas en la cartera de productos de Microsoft o API fáciles de usar como Azure Cognitive Services, Azure Semantic Search y la nueva API OpenAI de Azure. Además, continuaremos el trabajo con la comunidad académica y de investigación para mejorar aún más los aspectos de IA responsable en el entrenamiento y uso de nuestros modelos a través del Programa Académico de Turing.
Nuestro compromiso de compartir los componentes clave de estos modelos como plataforma a través de código abierto sigue sólido. Innovamos de manera continua en DeepSpeed, ONNX Runtime y las recetas de capacitación en Azure Machine Learning para ampliar los límites de la eficiencia para entrenar y servir los modelos y aumentar la escala de los modelos a billones de parámetros. Continuaremos con la democratización del acceso y la capacidad de entrenar o adaptar modelos base cada vez más grandes e implementar estos modelos en la nube.
La convergencia de innovaciones en infraestructura, software de aceleración de aprendizaje automático, servicio de plataforma y modelado impulsado por tecnología en la nube ha creado las condiciones perfectas para acelerar la innovación en IA. Esto mejorará el acceso a esta poderosa tecnología para permitir que cada empresa se convierta en una empresa de tecnología de IA y para ayudarlos a lograr sus objetivos comerciales de manera más efectiva. Esperamos ver las emocionantes aplicaciones y experiencias que pueden crear con la pila de tecnología para IA a Escala.
Comiencen con la plataforma IA a Escala
Los desarrolladores tienen acceso a esta avanzada tecnología de IA hoy a través de la siguiente gama de herramientas y recursos:
Servicios de API
- API sobre potentes modelos de aprendizaje automático: Azure Cognitive Services para lenguaje, visión por computadora y más, Azure Cognitive Search y modelos de lenguaje avanzado de Azure OpenAI Service.
Modelos de IA pre-entrenados
- Los clientes interesados en utilizar nuestros modelos básicos de Turing de manera directa para su propia tarea específica pueden enviar una solicitud para unirse a Turing Private Preview. Además, ponemos nuestros modelos a disposición de académicos e investigadores para proyectos colaborativos a través del Programa Académico Microsoft Turing.
Servicios de aprendizaje automático
- Plataforma completa de desarrollo/implementación de aprendizaje automático: servicios Azure Machine Learning para seguimiento de experimentos, capacitación distribuida, contenedores seleccionados, MLOps, herramientas de IA responsable y alojamiento de modelos para inferencia. También ofrecemos PyTorch Enterprise para Azure, que incluye soporte a largo plazo, solución de problemas priorizada e integración con soluciones de Azure.
- Sistemas sin código o con código bajo basados en la nube: Power Apps/AI Builder y Azure Automated Machine Learning.
Infraestructura
- Infraestructura en la nube: instancias y clústeres de GPU de Azure con conectividad InfiniBand opcional; variedad de opciones de almacenamiento en la nube con Azure Blobs o Azure Data Lake Storage y bases de datos Azure SQL; almacenamiento de datos, gobernanza y análisis en bases de datos relacionales y lagos de datos no estructurados en Azure Synapse.
Herramientas
- Software de aceleración de aprendizaje automático de código abierto: DeepSpeed y ONNX Runtime para capacitación e inferencia, incluido soporte para dispositivos móviles y web.
- Herramientas para desarrolladores: Visual Studio Code es el editor/depurador de código de código abierto más popular con extensiones para el desarrollo de Python y el aprendizaje automático. GitHub CodeSpaces es un entorno de desarrollo alojado en la nube con tecnología de Visual Studio Code.
Gopi Kumar, Jiayuan Huang, Nguyen Bach y Luis Vargas, de la oficina del equipo de CTO de Microsoft, contribuyeron a este artículo.
Imagen principal: Foto cortesía de Microsoft.