Las capacidades de aprendizaje automático responsable de Microsoft generan confianza en los sistemas de IA, afirman los desarrolladores
Quienes manejan un negocio, saben lo difícil que es denunciar las actividades ilícitas de un cliente. Por lo tanto, antes de que los integrantes de la unidad de detección de fraudes de Scandinavian Airlines acusen a un cliente de intentar estafar el programa de puntos de lealtad de la aerolínea, los detectives necesitan asegurarse de que su caso sea sólido.
“Sería incluso más perjudicial para nosotros decir que algo es fraude cuando no lo es”, comentó Daniel Engberg, director de analítica de datos e inteligencia artificial en SAS, cuya sede se ubica en Estocolmo, Suecia.
La aerolínea ha reducido sus vuelos y limitado sus servicios a bordo para ayudar a mitigar la propagación del COVID-19, la enfermedad causada por el nuevo coronavirus. Antes de las restricciones, SAS gestionaba más de 800 salidas al día y 30 millones de pasajeros al año. Conservar la integridad del programa de lealtad EuroBonus es fundamental mientras la aerolínea reanuda sus operaciones normales, agregó Engberg.
Los estafadores de EuroBonus, explicó, intentan acumular puntos lo más rápido posible ya sea para reservar vuelos de premio para ellos mismos o para venderlos. Cuando ocurre un fraude, los clientes legítimos pierden la oportunidad de solicitar los asientos reservados para el programa de lealtad y SAS deja de ganar ingresos considerables.
Hoy, una gran parte de la información sobre los fraudes a EuroBonus proviene de una sistema de inteligencia artificial (IA) que Engberg y su equipo desarrollaron con Microsoft Azure Machine Learning, un servicio para desarrollar, entrenar e implementar modelos de aprendizaje automático que son fáciles de entender, proteger y controlar.
El sistema de IA de SAS procesa flujos de datos, operaciones y reclamos de premios, entre otros, en tiempo real a través de un modelo de aprendizaje automático con miles de parámetros para detectar los patrones de comportamiento sospechoso.
Para entender las predicciones de los modelos y, de esa forma, seguir las pistas y armar sus casos, la unidad de detección de fraudes depende de una capacidad de Azure Machine Learning llamada interpretación, impulsada por el paquete de herramientas InterpretML. Esta capacidad explica qué parámetros fueron los más importantes en un caso determinado. Por ejemplo, podría señalar los parámetros que sugieren un fraude de acumulación de puntos desde cuentas fantasmas para reservar vuelos.
Las capacidades interpretativas de los modelos ayudan a resolver el misterio del aprendizaje automático, lo cual, a su vez, puede generar confianza en las predicciones de los modelos, señaló Engberg.
“Si generamos confianza en estos modelos, las personas comenzarán a utilizarlos y entonces podremos empezar a recibir los beneficios que promete el aprendizaje automático”, dijo. “No se trata de explicar solo por el hecho de explicar, sino de poder ofrecer tanto a nuestros clientes como a nuestros empleados información sobre qué hacen estos modelos y cómo nos ayudan”.
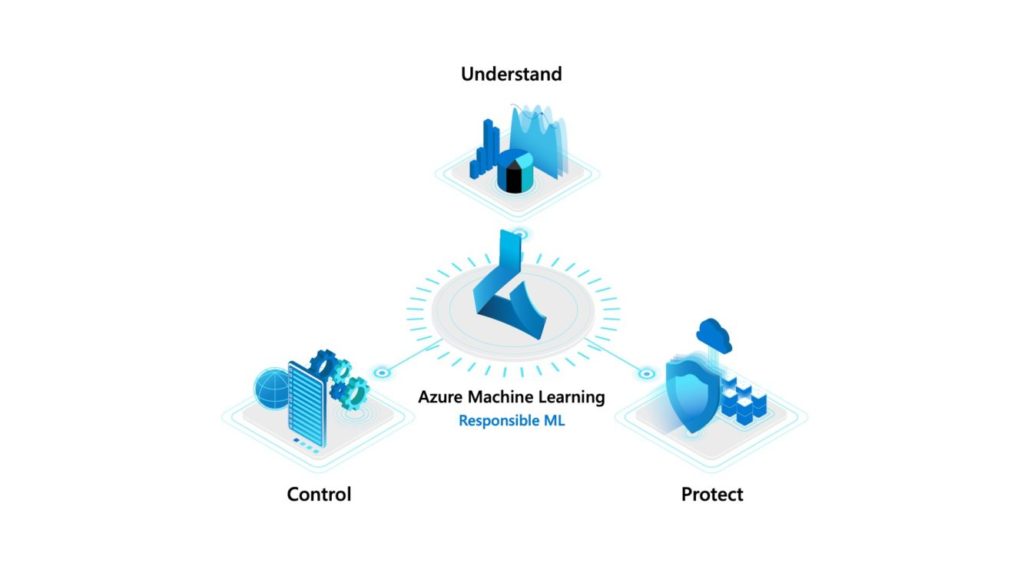
Entender, proteger y controlar su solución de aprendizaje automático
A lo largo de los últimos años, el aprendizaje automático ha salido de los laboratorios de investigación para integrarse en lo cotidiano, y se ha transformado de una disciplina de nicho para científicos de datos con doctorado, en una disciplina en que la todos los desarrolladores pueden participar, observó Eric Boyd, vicepresidente corporativo de Microsoft Azure AI en Redmond, Washington.
Microsoft creó Azure Machine Learning para permitir que los desarrolladores con diferentes niveles de experiencia en ciencia de los datos puedan desarrollar e implementar sistemas de IA. Hoy, a los desarrolladores se les pide cada vez más que desarrollen sistemas de IA que sean fáciles de explicar y que cumplan con las regulaciones de privacidad y de no discriminación, puntualizó Boyd.
Y agregó: “Es muy difícil emitir un buen juicio respecto a ‘¿En verdad sé si mi modelo se comporta de manera imparcial?’ o ‘¿En realidad entiendo por qué este modelo en particular predice de la manera en que lo hace?’”.
Para superar estos obstáculos, Microsoft anunció innovaciones en aprendizaje automático responsable que pueden ayudar a los desarrolladores a entender, proteger y controlar sus modelos a lo largo del ciclo de vida del aprendizaje automático. Estas capacidades se pueden obtener a través de Azure Machine Learning y también están disponibles en código abierto en GitHub.
Para poder entender el comportamiento de un modelo, se requieren las capacidades interpretativas impulsadas por el paquete de herramientas InterpretML que SAS utiliza para detectar el fraude en su programa de lealtad EuroBonus.
Asimismo, Microsoft afirmó que el paquete de herramientas Fairlearn, que incluye capacidades para evaluar y mejorar la imparcialidad de los sistemas de IA, se integrará en Azure Machine Learning en junio de 2020.
Microsoft también anunció que WhiteNoise, un paquete de herramientas para privacidad diferencial, ya está disponible en código abierto en GitHub para que los desarrolladores experimenten con él, así como a través de Azure Machine Learning. Las capacidades de privacidad diferencial se desarrollaron en colaboración con investigadores del Instituto de Ciencias Sociales Cuantitativas y la Escuela de Ingeniería de Harvard.
Las técnicas de privacidad diferencial permiten obtener información de valor de los datos privados, además de ofrecer certezas estadísticas que aseguran que la información privada como nombres o fechas de nacimiento se pueda proteger.
Por ejemplo, la privacidad diferencial podría permitir que un grupo de hospitales colabore para desarrollar un mejor modelo predictivo sobre la eficacia de los tratamientos de cáncer y, al mismo tiempo, ayudar a cumplir los requisitos legales para proteger la privacidad de la información del hospital y asegurar que no haya fugas de datos del paciente.
Azure Machine Learning también cuenta con controles integrados que permiten a los desarrolladores monitorear y automatizar todo el proceso de desarrollo, entrenamiento e implementación de un modelo. Esta capacidad, conocida por muchos como aprendizaje automático y operaciones (MLOps, por sus siglas en inglés) proporciona un registro de auditoría que ayuda a las organizaciones a adherirse a los requisititos regulativos y de cumplimiento.
“MLOps consiste en considerar el aspecto operativo y repetitivo del aprendizaje automático, es decir, la manera en que se registran los diferentes experimentos que se conducen, los parámetros que se definieron con ellos y los conjuntos de datos que se utilizaron para crearlos”, dijo Boyd. “Y luego utilizar esa información para recrear esos mismos procesos”.

Bandidos contextuales y responsabilidad
A mediados de los años 2010, Sarah Bird y sus colegas del laboratorio de investigación de Microsoft en Nueva York trabajaron en una tecnología de aprendizaje automático llamada bandidos contextuales que, a través de experimentos exploratorios, aprenden a realizar tareas específicas de forma cada vez mejor con el paso del tiempo.
Por ejemplo, si un visitante a un sitio web nuevo pulsa en un artículo sobre gatos, el bandido contextual aprende a ofrecer al visitante más artículos sobre gatos. Para aprender más, el bandido realiza experimentos como mostrar al visitante artículos sobre los Jacksonville Jaguars, un equipo de futbol americano, y sobre el exitoso musical Cats. El artículo que el visitante seleccione constituye otro dato de aprendizaje que conduce a una mayor personalización.
“Cuando funciona, es asombroso, pues obtienes niveles de personalización nunca antes vistos”, dijo Bird, quien ahora dirige todos los esfuerzos de IA responsable en Azure AI. “Empezamos a conversar con nuestros clientes y a colaborar con nuestros equipos de ventas para ver quién quería utilizar la versión piloto de esa innovadora tecnología de investigación”.
Los prospectos de ventas hicieron reflexionar a Bird. A medida que los clientes potenciales presentaban ideas sobre cómo utilizar bandidos contextuales para optimizar el proceso de entrevistas de trabajo y las adjudicaciones de reclamos de seguros, se percató de que mucha gente no entendía la manera en que funcionaban los bandidos.
“Comencé a preguntarme: ‘¿Siquiera es ético conducir experimentos en esos casos?’”, recordó Bird.
La pregunta dio lugar a debates con colegas en el grupo de investigación Imparcialidad, responsabilidad, transparencia y ética en la IA (FATE, por sus siglas en inglés) y a una colaboración de investigación sobre la historia de la ética experimental y las implicaciones para el aprendizaje reforzado, que es el tipo de aprendizaje automático detrás de los bandidos contextuales.
“La tecnología es tan buena que la hemos comenzado a utilizar en casos reales, y si la usamos en casos reales que afectan la vida de las personas, entonces más vale que nos aseguremos de que sea imparcial y segura”, dijo Bird, que ahora se dedica de tiempo completo al desarrollo de herramientas que brindan a los desarrolladores acceso a un aprendizaje automático responsable.
Perros siberianos, lobos y estafadores
En tan solo unos cuantos años, la investigación de la IA ética se había disparado en todo el mundo. Temas como la interpretación e imparcialidad de los modelos eran populares en las conferencias más importantes de la industria, y las herramientas de aprendizaje automático responsable se describían en la literatura académica.
En el 2016, por ejemplo, Marco Tulio Ribeiro, que en el actualidad se desempeña como investigador ejecutivo en el laboratorio de investigación de Microsoft en Redmond, presentó una técnica en un ensayo académico para explicar la predicción de cualquier clasificador, tales como modelos de visión informática entrenados para clasificar objetos en las fotografías.
Para demostrar la técnica, Ribeiro entrenó de manera deliberada un clasificador para predecir “lobo” si una fotografía tenía un fondo nevado y “perro siberiano” si no había nieve. Luego, ejecutó el modelo en fotografías de lobos con un fondo nevado y de perros siberianos sin un fondo nevado y presentó los resultados ante expertos en aprendizaje automático con dos preguntas: ¿Confían en este modelo? y ¿Cómo realiza las predicciones?

Muchos de los expertos en aprendizaje automático dijeron que confiaban en el modelo y presentaron teorías sobre por qué predecía lobos o perros siberianos, tales como que los lobos tienen dientes más filosos, observó Ribeiro. Menos de la mitad mencionaron el fondo como un factor potencial y nadie hizo alusión a la nieve.
“Luego les mostré las explicaciones, y, después de verlas, por supuesto que todos entendieron y dijeron: ‘Ah, solo observa el fondo’”, dijo. “Esta es una prueba de concepto; un mal modelo puede engañar incluso a los expertos”.
Una versión mejorada de la técnica de explicación de Ribeiro es una de las varias capacidades interpretativas disponibles para los desarrolladores que utilizan la interpretación en Azure Machine Learning, el paquete de herramientas que la unidad de detección de fraudes de SAS utiliza para armar casos contra los estafadores del programa de lealtad EuroBonus.
Otras soluciones de IA que SAS ha comenzado a desarrollar con Azure Machine Learning consisten en un método que pronostica las ventas de boletos y un sistema que optimiza el abastecimiento de alimentos frescos para las compras a bordo. La solución de alimentos frescos redujo el desperdicio de comida en más de 60 % antes de que la venta de alimentos frescos se detuviera como parte de los esfuerzos globales para mitigar la propagación del COVID-19.
Engberg y su equipo de análisis de datos e inteligencia artificial continúan el desarrollo, entrenamiento y pruebas de modelos de aprendizaje automático, que incluyen experimentos más amplios con las capacidades de interpretación e imparcialidad de Azure Machine Learning.
“Entre más estudiemos las cosas que afectan a nuestros clientes o a nosotros como personas, pienso que más importantes serán estos conceptos de imparcialidad, IA explicable e IA responsable”, dijo Engberg.
Evaluar y mitigar la parcialidad
Los colegas de Bird en FATE inventaron muchas de las capacidades del paquete de herramientas Fairlearn. Las capacidades permiten a los desarrolladores analizar la eficacia del modelo en grupos de personas con base en el género, el tono de piel, la edad y otras características.
“Puedes tener una buena idea de lo que la imparcialidad significa en una aplicación y, debido a la complejidad de estos modelos, podrías incluso no darte cuenta de que no funciona de la misma manera para un grupo de personas y para otro”, explicó Bird. “Fairlearn permite detectar esas cuestiones”.

EY, un líder global en servicios de auditoría, asesoría fiscal, asesoría en transacciones y consultoría, probó las capacidades de imparcialidad del paquete de herramientas Fairlearn en un modelo de aprendizaje automático que la empresa desarrolló para decisiones de préstamo automatizadas.
El modelo se entrenó con los datos de concesión de créditos hipotecarios de los bancos, los cuales incluyen historial de transacciones y de pagos e información del buró de crédito. Este tipo de datos por lo general se utiliza para evaluar la capacidad y disposición del cliente para pagar un préstamo. Sin embargo, también plantea inquietudes respecto a las cuestiones legales y a la posible imparcialidad hacia los solicitantes de ciertas demografías.
EY utilizó Fairlearn para evaluar la imparcialidad de los resultados del modelo en relación con el sexo biológico. El paquete de herramientas, que presentó los resultados en un panel visual e interactivo, mostró una diferencia de 15.3 puntos porcentuales entre las decisiones de préstamo positivas para hombres respecto a mujeres.
El paquete de herramientas Fairlearn permitió al equipo de EY desarrollar y entrenar de manera rápida varios modelos corregidos y observar la compensación común entre la parcialidad y la precisión del modelo. Al final, el equipo aterrizó en un modelo que optimizó y conservó la precisión en general pero que redujo la diferencia entre hombres y mujeres a 0.43 puntos porcentuales.
La capacidad de cualquier desarrollador para evaluar y mitigar la parcialidad en sus modelos se ha vuelto esencial en la industria financiera, señaló Boyd.
“Vemos cada vez más cómo los reguladores observan de cerca estos modelos”, dijo. “Poder documentar y demostrar que siguieron las prácticas más eficaces y que se esforzaron por mejorar la imparcialidad de los conjuntos de datos es fundamental para que puedan seguir con sus operaciones”.
Aprendizaje automático responsable
Bird piensa que el aprendizaje automático ha comenzado a cambiar el mundo para bien, pero afirma que todos los desarrolladores necesitan las herramientas y recursos para construir modelos en maneras que prioricen la responsabilidad.
Consideremos, por ejemplo, una colaboración en investigación dentro de la comunidad médica para compilar conjuntos de datos de pacientes con COVID-19 y desarrollar un modelo de aprendizaje automático que prediga quién está en riesgo de presentar complicaciones graves relacionadas con el coronavirus.
Antes de implementar dicho modelo, dice Bird, los desarrolladores necesitan entender la manera en que toma decisiones para poder explicar el proceso a los médicos y los pacientes. Los desarrolladores también deberán evaluar la imparcialidad con el fin de garantizar que el modelo capture, por ejemplo, los riesgos conocidos para los hombres.
“No quiero un modelo que nunca prediga que los hombres están en riesgo; eso sería terrible”, afirma Bird. “También es importante, por razones obvias, asegurarse de que el modelo no revele los datos de las personas con las cuales se entrenó, de modo que es necesario utilizar la privacidad diferencial”.
Imagen superior: Una herramienta de detección de fraudes impulsada por IA de SAS, procesa flujos de datos, operaciones y reclamos de premios a través de un modelo de aprendizaje automático para detectar los patrones de comportamiento sospechoso. Una capacidad de Azure Machine Learning llamada interpretación, explica qué parámetros del modelo fueron los más importantes en un caso determinado de sospecha de fraude. Foto cortesía de SAS.