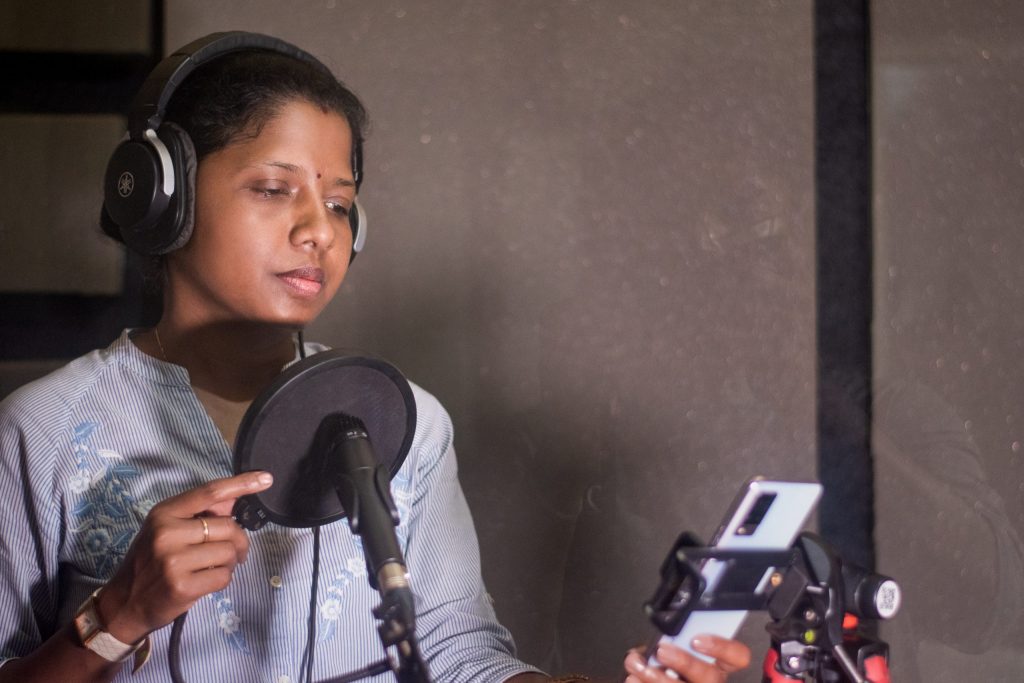
Proyecto de Microsoft Research ayuda a los idiomas a sobrevivir y prosperar
 Amal Shiyas
News Center Microsoft India
Amal Shiyas
News Center Microsoft India
Una mujer llamada Boa Sr fue el último eslabón de una cultura preneolítica de 65 mil años de antigüedad en las Islas Andamán en el Océano Índico. Cuando ella murió en 2010, el idioma bo también murió y se extinguió.
Si eso suena como un incidente aislado, no lo es. Cada dos semanas se pierde una lengua en algún lugar del mundo.
Tomemos como ejemplo a los mundas, una comunidad de alrededor de un millón de personas repartidas por los estados de Jharkhand, Orissa y Bengala Occidental, en el este de la India.
“Aprendí Mundari muy tarde porque mis padres vivían en otro estado donde trabajaban, por lo que no hablábamos el idioma en casa”, dice la Dra. Meenakshi Munda, miembro de la comunidad de Munda y profesora asistente en la departamento de antropología de una universidad en Ranchi, Jharkhand. “Entiendo cómo la identidad es importante para una comunidad y nuestra generación más joven ha comenzado a perder su identidad porque no conocen su idioma”.
La comunidad de Munda está preocupada por la longevidad de su idioma, ya que en las escuelas solo se enseñan idiomas destacados como el bengalí, el hindi y el odiya.
Si bien hay una letra escrita para Mundari, tiene un contenido digital o una presencia en línea insignificantes, lo que brinda aún menos incentivos para que las personas inviertan en aprender el idioma.
Un puñado de investigadores del laboratorio de Microsoft Research (MSR) en India ha trabajado para crear ecosistemas digitales para idiomas, como Mundari, que no tienen suficiente presencia en el mundo digital.
“La forma en que defino mi trabajo para mí es que ninguna persona en este mundo debería ser excluida del uso de ninguna tecnología porque habla un idioma diferente”, dice Kalika Bali de MSR India.
Bali es una experta en Procesamiento del lenguaje natural, el subcampo de la lingüística y la inteligencia artificial (IA) que se enfoca en capacitar a los sistemas informáticos para comprender los idiomas hablados y escritos.
Su equipo trabaja con comunidades locales y hablantes nativos para crear los conjuntos de datos básicos que se utilizarán para crear tecnologías de inteligencia artificial para idiomas con poca representación. Al involucrar a la comunidad en el proceso de recopilación de datos, esperan crear un conjunto de datos que sea preciso y relevante a nivel cultural.
El idioma de Internet, desde sus primeros años, ha sido el inglés. Desde entonces, con un mejor acceso a Internet y una demanda de contenido en idiomas nativos, otros siete idiomas hablados de manera amplia, incluidos el chino y el español, pueden igualar algo al inglés en términos de compatibilidad tecnológica. Pero eso es solo ocho de casi 6 mil idiomas en todo el mundo.
Esto significa que el 88 por ciento de los idiomas del mundo no tienen suficiente presencia en Internet. También significa que la friolera de 1,200 millones de personas, el 20% de la población mundial, no puede usar su idioma para navegar por el mundo digital.


“Como resultado, la distinción entre los que tienen y los que no tienen se volvió bastante marcada”, explica Monojit Choudhury, científico principal de datos y aplicado en Turing India de Microsoft y colega de Bali.
Los investigadores llaman a los idiomas que no tienen los recursos necesarios para construir tecnología para una presencia digital «lenguajes de bajos recursos».
En el marco del Proyecto ELLORA (Habilitación de idiomas de bajos recursos), la creación de recursos digitales tiene un doble propósito: primero, es un paso para preservar un idioma para la posteridad; y segundo, asegura que los usuarios de estos lenguajes puedan participar e interactuar en el mundo digital.
El proyecto ELLORA, lanzado en 2015, comenzó con lo básico. El primer paso fue mapear qué recursos ya estaban disponibles, como material impreso como literatura y el alcance de la presencia digital. En un documento de 2020, Bali y sus colegas describieron una clasificación de seis niveles, en el que el nivel superior representa idiomas ricos en recursos como el inglés y el español, y los niveles inferiores reflejan idiomas con pocos o ningún recurso.
El trabajo del Proyecto ELLORA consiste en recopilar los recursos necesarios para estos idiomas y construir modelos de lenguaje para satisfacer las necesidades digitales de sus hablantes.
Los investigadores del Proyecto ELLORA trabajan con las comunidades para definir cuál es esta necesidad y qué tecnología de base puede ayudar a satisfacerla. “Ninguna tecnología lingüística puede aislarse de las personas que la van a utilizar”, dice Bali.
Para Mundari, los investigadores colaboraron con IIT Kharagpur en 2018 y patrocinaron un estudio para encontrar lo que la comunidad necesita para mantener vivo el idioma.
Lo que comenzó como un simple juego de vocabulario para niños en edad escolar para que aprendieran el idioma pronto se transformó en sofisticados proyectos tecnológicos.
Los investigadores de MSR trabajan en la actualidad en una traducción de texto del hindi al mundari, así como en un modelo de reconocimiento de voz que brindará a la comunidad acceso a más contenido en mundari.
También se trabaja en un modelo de texto a voz, financiado bajo la iniciativa «Forward – Inteligencia artificial para todos» de la Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) en nombre del Ministerio alemán de Cooperación Económica y Desarrollo.
Pero crear modelos de traducción de idiomas para un idioma que no tiene ningún contenido digital significativo para entrenar modelos de aprendizaje automático no es tarea fácil.
El equipo, dirigido por profesores del IIT Kharagpur, trabajó en un inicio con miembros de la comunidad para que tradujeran oraciones de manera manual del hindi al mundari.
Para acelerar la traducción, los investigadores de MSR desarrollaron una nueva tecnología llamada traducción automática interna (INMT, por sus siglas en inglés), que ayuda a predecir la siguiente palabra cuando alguien traduce entre idiomas.
“(INMT) permite que los humanos traduzcan de un idioma a otro de manera más efectiva. Si traduzco del hindi al mundari, cuando empiezo a escribir en mundari, me da sugerencias predictivas en el propio mundari. Es como el texto predictivo que obtienes en los teclados de los teléfonos inteligentes, excepto que lo hace en dos idiomas”, explica Bali.
Para construir el conjunto de datos para texto a voz, colaboraron con Karya, que comenzó como un proyecto de investigación de Vivek Seshadri, investigador principal de MSR. Karya es una plataforma de trabajo digital para capturar, etiquetar y anotar datos para construir modelos de inteligencia artificial y aprendizaje automático.
El equipo identificó a un hablante masculino de mundari y a la doctora Munda como la hablante femenina, a quienes se les dieron las oraciones traducidas para que las registraran. Grabaron las oraciones en la aplicación Karya en teléfonos inteligentes Android.
Las grabaciones, junto con el texto correspondiente, se cargan de forma segura en la nube y los investigadores pueden acceder a ellas para entrenar modelos de texto a voz.
“La idea es que, entre Microsoft Research, Karya e IIT Kharagpur, tengamos datos para traducción automática, reconocimiento de voz y síntesis de texto a voz, de modo que estas tres tecnologías puedan construirse para Mundari”, explica Bali.
Estas conexiones entre el lenguaje y la tecnología son bloques de construcción básicos que con el tiempo podrían habilitar sistemas sofisticados como servicios de traducción en sitios web gubernamentales o plataformas de transmisión. Estos sistemas ya son una realidad para el idioma en el que ustedes leen este artículo.

La comunidad de Munda no es la única incorporada al trabajo del Proyecto ELLORA. Otros esfuerzos de desarrollo del idioma nativo incluyen:
- Ayudar a los hablantes de gondi, muy pocos de los cuales entienden otros idiomas, a obtener acceso a la información. Project ELLORA trabajó con los socios CGNETSwara y IIIT Naya Raipur para construir Adavasi Radio, un centro donde se puede acceder a noticias, videos y libros. El equipo produjo 60 mil oraciones paralelas entre gondi e hindi, lo que llevó al desarrollo de un servicio de traducción automática.
- Trabajar con la comunidad Idu Mishmi en Arunachal Pradesh, en el noreste de India, para crear un marco para un diccionario digital para el idioma Idu Mishmi, que ahora tiene menos de 12 mil hablantes. El diccionario digital se utilizará en las escuelas para enseñar Idu Mishmi a los niños.
“Queremos acortar el ciclo de tiempo que, de lo contrario, podría llevar a estos idiomas tener suficientes datos para aprovechar la tecnología”, dice Bali. “Si la IA puede hacer todas estas cosas maravillosas para los hablantes de inglés, entonces debería poder hacer todas estas cosas maravillosas para cualquier otro ser humano que no hable inglés”.
Foto superior: la doctora Meenakshi Munda graba muestras de voz de texto en Karya para ayudar a construir modelos de texto a voz para Mundari. Foto de SunilBisoyi para Microsoft.
Amal Shiyas es editora asistente en FiftyTwo.in.