Un mapa del universo con SQL Server
![]() News Center LATAM
News Center LATAM
Este artículo de blog fue escrito conjuntamente por Joseph Sirosh, Vicepresidente Corporativo, y Rimma V. Nehme, Ingeniera Principal de Software, en el Grupo de Datos de Microsoft.

Durante los últimos 15 años, una base de datos ha ayudado a revolucionar todo un campo científico. El descubrimiento astronómico y el análisis sofisticado de las propiedades del universo entero evolucionaron de manera drástica gracias a un inmenso esfuerzo público para trazar un mapa del cielo, llamado Sloan Digital Sky Survey, cuyos datos se alimentaron en una base de datos pública desarrollada con Microsoft SQL Server. Ésta fue una innovación en el campo y abrió una ventana completamente nueva hacia el universo.

Hoy en día, los científicos en todos los campos, desde la astronomía hasta la zoología, reconocen que la velocidad a la cual se acumulan los datos en sus campos está superando por mucho la velocidad a la que esos datos se pueden interpretar; por ejemplo, la velocidad a la cual la comunidad científica pueden asimilar los datos en una estructura de trabajo interpretativa. Asimismo, se reconoce ampliamente que los descubrimientos científicos importantes yacen ocultos en esos datos tan masivos. El Cuarto Paradigma del descubrimiento científico, conducido por técnicas innovadoras para analizar datos masivos, se ha convertido en la principal fuerza propulsora dentro de la ciencia.
Sloan Digital Sky Survey: El Proyecto del Genoma Cósmico
Todo comenzó a principios de los años 90, cuando el Dr. Alex Szalay y el ya fallecido Dr. Jim Gray emprendieron la osada tarea de construir lo que podría llamarse el primer “DataScope” —una eficiente infraestructura de cómputo intensivo de datos para astrónomos denominada Sloan Digital Sky Survey (SDSS)— utilizando Microsoft SQL Server como la base de datos back-end.

SDSS tenía un objetivo ambicioso: crear un mapa del universo en una base de datos que cualquiera pudiera explorar. Con frecuencia se le conoce como el Proyecto del Genoma Cósmico. Un telescopio de 2.5 m de diámetro en Nuevo México utilizó una cámara de 120 megapíxeles para crear una imagen de más de una cuarta parte del cielo nocturno, 1.5 grados cuadrados de cielo a la vez, cerca de ocho veces el área de la luna, tanto dentro como fuera de la Vía Láctea, y ayudó a crear un mapa tridimensional (3D) de millones de galaxias, cuásares y estrellas.
Los mapas de SDSS desataron una revolución en cuanto a la manera en que se practica la astronomía. Los científicos ya no tenían que esperar meses para acceder a un telescopio para estudiar el cielo nocturno; ahora todos los proyectos de investigación se podían llevar a cabo con sólo consultar la base de datos en línea. El SDSS puso a disposición todo su conjunto de datos a través de la base de datos SkyServer —un portal en línea de uso público— e invitó a todos a contribuir voluntariamente a la investigación científica. Antes de SDSS, sólo los principales científicos y astrónomos contaban con telescopios e instrumentos para recopilar datos para investigaciones importantes, mientras que a los demás se les impedía participar directa y activamente en los proyectos astronómicos. Ahora, con el acceso a los datos visuales que ofrece SkyServer, cualquiera con acceso a Internet puede explorar el universo mediante datos, tal y como lo hacen los científicos más renombrados.

La arquitectura de SkyServer era bastante sencilla: un servidor IIS front-end aceptaba solicitudes HTTP procesadas por JavaScript Active Server Pages (ASP). Esos guiones utilizaban Active Data Objects (ADO) para consultar la base de datos back-end de Microsoft SQL Server. SQL Server produjo conjuntos de registros que JavaScript formateó en páginas. El sitio web era de unas 40,000 líneas de código y lo construyeron dos personas en su tiempo libre.
¿Por qué Microsoft SQL Server?
Mientras desarrollaban aplicaciones para estudiar la propiedades correlativas de las galaxias, Szalay y su equipo descubrieron que muchos de los patrones en su análisis estadístico contenían tareas que se podían realizar mucho mejor dentro del motor de la base de datos que fuera de éste, sobre archivos planos. Microsoft SQL Server les proporcionó una búsqueda secuencial a alta velocidad de predicados complejos utilizando múltiples CPUs, múltiples discos, y memorias principales grandes. También contaba con indexación sofisticada y algoritmos de unificación de datos que superaban en extremo los programas escritos a mano respecto a los archivos planos. Muchos de los archivos de procesamiento por lotes que se generaban a diario se reemplazaron con consultas de base de datos que se ejecutaban en minutos gracias al sofisticado optimizador de consultas.
Impacto

La versión más reciente de la base de datos tiene un conjunto de datos de 15TB para consulta pública, con unos 150TB de archivos sin procesar y calibrados adicionales. Un escaneo reciente de los registros mostró más de 1,600 millones visitas en los últimos 14 años y más de cuatro millones de diferentes direcciones de IP que accedieron al sitio. El número total de astrónomos profesionales a nivel mundial es de sólo 15,000. Además, el ambiente colaborativo y multiusuario de SDSS, llamado CasJobs, que permite a los usuarios conducir análisis extensos, cuenta con más de 6,820 usuarios registrados —casi el doble que la comunidad de astrónomos profesionales—.
SDSS ha generado con éxito nuevos descubrimientos científicos, incluyendo la medición de miles de asteroides, mapas de la complicada historia de fusión del exterior de la Vía Láctea, y la primera detección del pico acústico bariónico —una escala que mide cómo se formó la estructura a partir de ondas sonoras de baja frecuencia en los inicios del universo—. Estos estudios han producido datos suficientes para apoyar 5,800 ensayos con más de 245,000 citas, lo que convierte a SDSS en uno de los proyectos de mayor impacto en el campo de la astronomía.
Los datos de SkyServer
SkyServer contiene una cantidad de datos astronómicos sin precedentes. Cuando el SDSS comenzó en 1998, los astrónomos tenían datos de menos de 200,000 galaxias. En los cinco años posteriores al desarrollo de SDSS, SkyServer ya contaba con datos sobre 200 millones de galaxias en su base de datos. Hoy, los datos de SDSS superan los 150 terabytes y abarcan más de 220 millones de galaxias y 260 millones de estrellas. Las imágenes por sí solas incluyen 2.5 trillones de píxeles de datos originales sin procesar. SkyServer permite a los usuarios buscar estrellas en determinada posición en el cielo o buscar galaxias más brillantes que un cierto límite. Los usuarios también pueden ingresar consultas en la base de datos directamente en SQL, lo que permite conducir búsquedas más flexibles y sofisticadas.
Ejemplos de consultas que los usuarios pueden realizar en SkyServer:
- ¿Qué recursos hay en esta parte del cielo?
- ¿Cuál es área común de estos mapas?
- ¿Este punto se encuentra en el mapa?
- Muéstrame todos los objetos en esta región
- Muéstrame todos los objetos “buenos” (excluye las áreas “malas”)
- Proporcióname los números acumulativos sobre las áreas
- Calcula las transformaciones esféricas rápidas de las densidades
- Interpola la funciones de muestreo disperso (mapas de extinción, temperatura del polvo, …)
Galaxy Zoo

Otro proyecto que ha sido posible a través del acceso a los datos de SDSS es un sitio web de “citizen science” llamado Galaxy Zoo, donde usuarios de Internet han clasificado de manera voluntaria las galaxias utilizando las imágenes de SDSS. Por lo general, los astrónomos solían clasificar las galaxias a vista de ojos. Si tienes 200 millones de galaxias, a tres por minuto en promedio, la clasificación tomará 600 millones de minutos o 1,142 años de 24 horas al día, los siete días de la semana. Galaxy Zoo fue el primer portal astronómico de colaboración colectiva que permitió a los ciudadanos privados ver los datos y aportar clasificaciones para los científicos en un tiempo mucho más corto.
Se han realizado varios descubrimientos científicos utilizando Galaxy Zoo, incluyendo la determinación de la relación entre la morfología de las galaxias y su ambiente y el descubrimiento de Hanny’s Voorwerp —un tipo muy raro de objeto astronómico llamado echo de ionización de un cuásar— por un profesor de escuela holandés. Esos descubrimientos no hubieran sido posibles sin la participación de miles de voluntarios de Galaxy Zoo, quienes han clasificado más de 40 millones de galaxias hasta la fecha—.
De SkyServer a SciServer: Una infraestructura de Big Data para la ciencia
Un nuevo esfuerzo denominado SciServer, descendiente de SkyServer, busca trascender el campo de la astronomía para construir un ecosistema flexible a largo plazo para que los científicos otorguen acceso a los enormes conjuntos de datos de las observaciones y de las simulaciones para promover la investigación colaborativa. SciServer busca cumplir los retos del Big Data en el mundo de la ciencia. Al construir una infraestructura común, el objetivo es proporcionar acceso a datos y a herramientas de análisis que resulten útiles en todas las áreas científicas. Dirigido por Alex Szalay, el trabajo en SciServer brindará beneficios importantes a la comunidad científica, ya que extenderá la infraestructura desarrollada para los datos astronómicos de SDSS hacia muchas otras áreas de la ciencia.
Para diseñar SciServer se aplicó el mismo enfoque que en SkyServer: llevar el análisis a los datos. Eso significa que los científicos pueden buscar y analizar el Big Data sin descargar terabytes o petabytes de datos, lo que acelera en extremo los tiempos de procesamiento. Llevar el análisis a los datos también simplifica considerablemente la comparación y combinación de los conjuntos de datos, lo que permite a los investigadores descubrir nuevas y asombrosas conexiones entre los datos y reproducir los experimentos con mayor facilidad.
Para ayudar a aligerar la carga de los investigadores, el equipo desarrolló SciDrive, un sistema de almacenamiento de datos científicos en la nube que permite a los científicos subir y compartir los datos utilizando una interfaz similar a Dropbox. La interfaz lee los datos automáticamente en la base de datos y la persona puede buscar en línea y correlacionar los datos con otras fuentes de datos. SciDrive intenta resolver la “larga estela” de la cantidad gigantesca de conjuntos de datos pequeños de los científicos. El objetivo consiste en intentar reunir muchos datos pequeños aparentemente no relacionados en un solo lugar y ver si emerge un nuevo valor. La gente puede simplemente arrastrar y soltar (y compartir) sus datos sin la necesidad de metadatos.
Y en el corazón de todo eso está SQL Server
El equipo de SDSS, en colaboración con Jim Gray, asumió la enorme tarea de ingresar todos los datos astronómicos en la base de datos SQL Server, enfocándose en conservar las fuentes originales lo más posible y en hacer que los datos se pudieran acceder y consultar en forma sencilla.
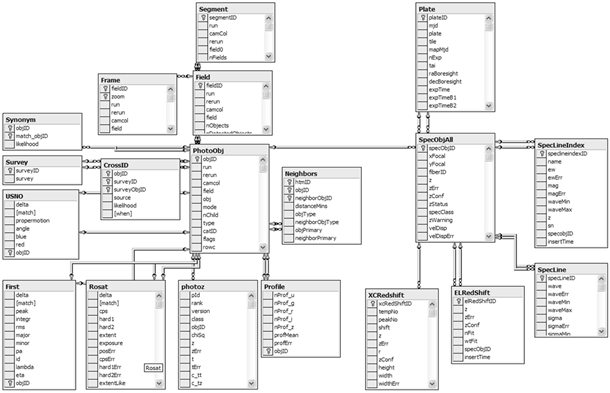
Un diseño lógico para la base de datos

Los datos de las imágenes procesadas se almacenaron en bases de datos. El diseño lógico de la base de datos consistió en objetos fotográficos y espectrográficos. Se organizaron en un par de diagramas de copo de nieve. Las vistas de los subconjuntos y la extensa cantidad de índices otorgan acceso conveniente y rápido a los subconjuntos convencionales (tales como estrellas y galaxias). Los procedimientos e índices se definieron para acelerar aún más la búsqueda espacial.
El diseño físico de la base de datos
En un inicio, SkyServer aplicó un enfoque sencillo para el diseño de la base de datos (véase la Figura 11 abajo), el cual funcionó bien desde el principio. El diseño dependía del motor de almacenamiento SQL y del optimizador de consultas para tomar todas las decisiones inteligentes sobre la distribución de los datos y el acceso a los datos. Alex Szalay comenta: “El excelente optimizador de consultas marcó toda la diferencia. ¡Incluso los ‘peores’ planes de consulta resultaron bastante buenos!”
“Indexar el cielo”
Para acelerar el acceso, las tablas de base se indexaron ampliamente (esos índices también beneficiaron el acceso a la vista). Además de los índices, el diseño de la base de datos incluye un conjunto bastante completo de declaraciones clave para asegurar que cada perfil tenga un objeto, que cada objeto se encuentre dentro de un campo válido, y así sucesivamente. El diseño también insistió en que todos los campos fueran no nulos. Estas limitaciones de integridad fueron herramientas valiosas para detectar errores durante la carga de datos y facilitaron herramientas que navegan de manera automática por las bases de datos.
Además de desglosar el grupo de archivos (obtener automáticamente la suma de los anchos de banda de los discos sin esfuerzo por parte del usuario), SkyServer utilizó prácticamente todos los valores predeterminados de SQL Server, por lo que no se requirió una configuración especial. Esa es la gran ventaja de SQL Server —el sistema busca ofrecer un desempeño excelente desde el momento en que se instala, y el proyecto SkyServer ha sido prueba fiel de ese objetivo.
Acceso a datos espaciales
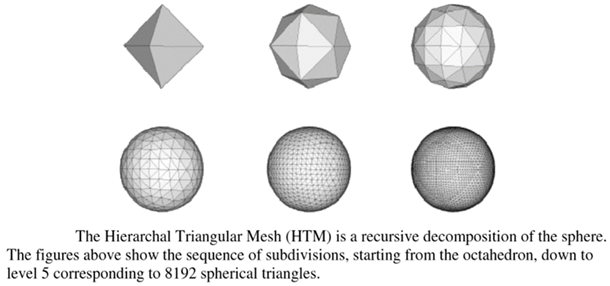
“Lo espacial era especial”. Los astrónomos se interesaron particularmente en ejecutar consultas espaciales para obtener un agrupamiento galáctico y una estructura de gran escala del universo. El elemento común de la experiencia con SDSS fue que permitió integrar los conceptos espaciales en una estructura relacional de forma muy sencilla. Para acelerar las consultas de las áreas espaciales, el equipo de SDSS integró el código del Hierarchical Triangular Mesh (HTM) en SQL Server, lo cual se convirtió en un nuevo “método de acceso espacial” en el motor. HTM es un método para subdividir la superficie de una esfera en triángulos esféricos de forma y tamaño similares, mas no idénticos. Básicamente, es un árbol cuaternario con la capacidad de soportar búsquedas a diferentes resoluciones, desde segundos de arcos hasta hemisferios. La biblioteca de HTM fue un procedimiento externo almacenado envuelto en un procedimiento almacenado de valores de tabla spHTM_Cover(<area>).
Por lo tanto, los usuarios sólo tenían que invocar una llamada a procedimiento similar a esta: select * from spHTM_Cover (‘Circle J2000 12 5.5 60.2 1’), lo cual devolverá la tabla con cuatro filas, cada una definiendo el comienzo y el final de un triángulo HTM de profundidad 12 como el que se muestra a continuación.
| HTMIDstart | HTMIDend |
| 3,3,2,0,0,1,0,0,1,3,2,2,2,0 | 3,3,2,0,0,1,0,0,1,3,2,2,2,1 |
| 3,3,2,0,0,1,0,0,1,3,2,2,2,2 | 3,3,2,0,0,1,0,0,1,3,2,2,3,0 |
| 3,3,2,0,0,1,0,0,1,3,2,3,0,0 | 3,3,2,0,0,1,0,0,1,3,2,3,1,0 |
| 3,3,2,0,0,1,0,0,1,3,2,3,3,1 | 3,3,2,0,0,1,0,0,1,3,3,0,0,0 |
Otra técnica de optimización empleada por SkyServer fue la idea de la zonificación (segmentar el espacio en cubos de zonas y luego segmentar las zonas por un offset). La idea principal detrás de la zonificación era intentar incorporar por completo la lógica en SQL (el código de zona era nativo para SQL), lo que permitió al optimizador de consultas realizar un trabajo de filtrado de objetos muy eficiente. En específico, el diseño de zonas triplicó la velocidad de las funciones con valores de tabla.
Soporte para CLR
En el 2005, la integración del tiempo de ejecución de lenguaje común (CLR, por sus siglas en inglés) .NET en SQL Server permitió a los astrónomos implementar código de usuario capaz de ejecutarse dentro del proceso de servidor de la base de datos. CLR fue una función muy importante para SDSS porque brindó a los astrónomos la capacidad de escribir lógica concretamente astronómica a manera de funciones definidas por el usuario, funciones de agregación y procedimientos almacenados para crear una funcionalidad específicamente científica y ejecutar el código compilado en la base de datos. En palabras de Alex: “El soporte para tipos orientados a objetos significó un cambio drástico para SkyServer”.
Consultas SQL
Los astrónomos deseaban una herramienta que tuviera la capacidad de responder rápidamente a consultas como: “encuentra candidatos a asteroides” o “encuentra otros objetos como éste”, que fue la razón original por la cual se construyó un backend basado en SQL. De hecho, desde el principio Jim Gray le pidió a Alex Szalay que definiera 20 preguntas típicas que a los astrónomos les gustaría realizar, y entonces diseñaron juntos la base de datos SkyServer para atender esas consultas. La anécdota es que la conversación se desarrolló así:
Jim: ¿Cuáles son las 20 preguntas que quieres hacer?
Alex: ¡Los astrónomos quieres preguntar muchas cosas! No sólo 20 preguntas.
Jim: De acuerdo, comencemos con 5 consultas.
[le tomó 30 minutos a Alex escribirlas]
Jim: De acuerdo, agrega otras 5 consultas.
[le tomó 1 hora a Alex escribirlas]
Jim: De acuerdo, ahora agrega otras 5 consultas.
[Alex se dio por vencido y se marchó a casa para pensar en ellas]
…
Alex (después dijo): ¡En 1.5 horas Jim me dio una gran lección de humildad!
…
Alex (después dijo): También nos enseñó la importancia de la distribución tardía y cómo priorizar.
Las consultas corresponden a las tareas típicas de los astrónomos. La traducción de las consultas en SQL requería un buen conocimiento de astronomía, un buen conocimiento de SQL y un buen conocimiento de bases de datos. Así lo comenta Alex: “Nos sorprendió y complació descubrir que las 20 consultas tenían equivalentes bastante simples en SQL”. A continuación se muestra uno de los ejemplos de las consultas utilizadas en SkyServer para detectar asteroides:
C: Proporciona una lista de objetos en movimiento consistentes con un asteroide.
select objID, -- return object ID sqrt( power(rowv,2) + power(colv, 2) ) as velocity, -– velocity dbo.fGetUrlExpId(objID) as Url -- url of image to examine it. into ##results from PhotoObj -- check each object. where (power(rowv,2) + power(colv, 2)) between 50 and 1000 -- square of velocity and rowv >= 0 and colv >=0 -- negative values indicate error
Este es un escaneo secuencial de la tabla PhotoObj para evaluar el predicado en cada uno de los objetos. Encuentra los candidatos a asteroides. Esta es la imagen de uno de dichos objetos:

La consulta de arriba arroja resultados de objetos de “movimiento lento”. Para encontrar objetos de movimiento rápido se puede escribir una consulta ligeramente diferente que busque rayas alineadas en el cielo. Esas rayas no están lo suficiente cerca para identificarse como un solo objeto.
SELECT r.objID as rId, g.objId as gId,
dbo.fGetUrlExpEq(g.ra, g.dec) as url
FROM PhotoObj r, PhotoObj g
WHERE r.run = g.run and r.camcol=g.camcol _ and abs(g.field-r.field)<2 -- nearby
-- the red selection criteria
and ((power(r.q_r,2) + power(r.u_r,2)) > 0.111111 )
and r.fiberMag_r between 6 and 22
and r.fiberMag_r < r.fiberMag_g
and r.fiberMag_r < r.fiberMag_i
and r.parentID=0 and r.fiberMag_r < r.fiberMag_u
and r.fiberMag_r < r.fiberMag_z
-- the green selection criteria
and ((power(g.q_g,2) + power(g.u_g,2)) > 0.111111 )
and g.fiberMag_g between 6 and 22 and g.fiberMag_g < g.fiberMag_r
and g.fiberMag_g < g.fiberMag_i
and g.fiberMag_g < g.fiberMag_u and g.fiberMag_g < g.fiberMag_z
and g.parentID=0
-- the matchup of the pair
and sqrt(power(r.cx -g.cx,2)+ power(r.cy-g.cy,2)+power(r.cz-g.cz,2))*(10800/PI())< 4.0
and abs(r.fiberMag_r-g.fiberMag_g)< 2.0_
And you can also add a third query
select top 10 ra, dec, (rowv*rowv + colv*colv ) as velocityVector, *
from PhotoObj
where
-- object SATURATED | BRIGHT | BLENDED and object DEBLENDED_AS_MOVING
(flags & (
cast(0x0000000000040000 as bigint) |
cast(0x0000000000000002 as bigint) |
cast(0x0000000000000008 as bigint) ) ) = 0
AND (flags & cast(0x0000000100000000 as bigint)) > 0
-- PSF magnitude / psfCount r r range between 14.5 and 21.5
AND type = 6
AND (psfMag_r > 14.5)
and (psfMag_r < 21.5)
-- veolocity vector larger than 0.05 deg/day and smaller than 0.5 deg/day.
AND (rowv*rowv + colv*colv > 0.0025)
AND (rowv*rowv + colv*colv < 0.25)
And dec > -1.25
AND dec < 1.25
-- Limit to specific part of the Stripe-82 region
AND (ra > 300 or ra < 60)
order by (rowv*rowv + colv*colv ) desc
Esta es la imagen de uno de dichos objetos de “movimiento más rápido”:

Cuando se le preguntó acerca de T-SQL, uno de los astrónomos respondió que era algo muy sencillo para ellos y que podían entender fácilmente lo que estaba ocurriendo. Otro astrónomo comentó: “SQL es como un ‘centro de soporte’. Si alguien tiene un problema, otra persona puede responder la pregunta cuando se le envía la consulta”. Un plan de consulta gráfico que es visible antes de realizar una consulta en MS-SQL indicó cuáles pasos de la consulta tomarían el mayor tiempo en ejecutarse y, en casi todos los casos, proporcionó a los usuarios la información necesaria para mejorar el desempeño de las consultas.
Configuración de hardware
La configuración de soporte para múltiples versiones en SDSS se muestra en la Figure 12 abajo. Los servidores de bases de datos DR12 (la versión más reciente) cuentan actualmente con la siguiente configuración de hardware:
- Tamaño total de datos: 12 TB
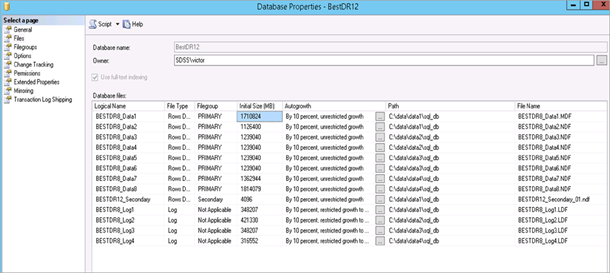
- Número de grupos de archivos: Dos (el Primario tiene 8 archivos, el Secundario tiene un archivo, véase la Figura 13)
- Servidores: Cuatro nodos idénticos, cada uno con una copia de la base de datos
- Fabricante del sistema: Supermicro
- Tipo de sistema: PC basada en x64
- Procesador(s): Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz (2 procesadores)
- Núcleos lógicos: 32
- CPUs físicas: 2
- Memoria física total: 128 GB
- Tamaño de la unidad de disco duro: 3.0 TB
- Total de unidades de disco duro: 24
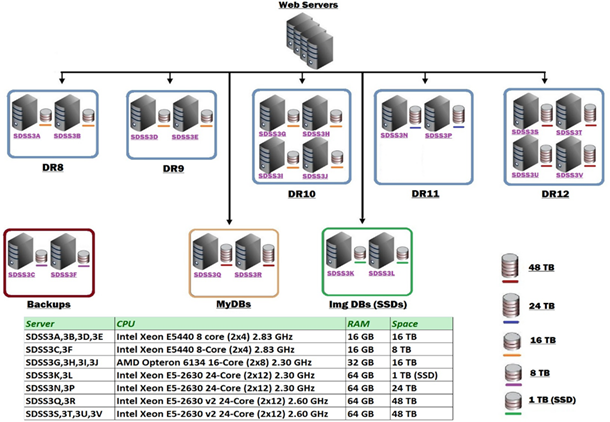
En el clúster de producción hay de tres a cuatro servidores de bases de datos por versión para poder soportar adecuadamente al público y a los usuarios colaboradores y para que las consultas se pueden equilibrar por carga en diferentes cajas. Las consultas rápidas y largas se canalizan a servidores independientes.
Conclusión
“Fue muy divertido trabajar en SDSS, y esperamos que la gente lo utilice. Trabajar con SQL Server fue divertido, pero la astronomía también es divertida”, afirma Alex Szalay. La ciencia está cada vez más orientada a los datos (masivos y pequeños) y a los cambios sociológicos —hoy en día, personas de todo el mundo, no sólo unos cuantos expertos, analizan mapas—. El cambio de una ciencia orientada a las hipótesis a una ciencia orientada a los datos es una realidad, y el SDSS impulsado por SQL Server es el primer “telescopio” de datos que ha hecho realidad la visión de un “DataScope”.
Joseph y Rimma
Siga a Joseph en Twitter en @josephsirosh y a Rimma en @rimmanehme.